Java基础
Java语法基础
==Java的优点==
简单、可移植、安全、并发
==JDK JRE JVM==

JDK(Java Development Kit)是用于开发 Java 应用程序的软件环境。里面包含运行时环境(JRE)和其他 Java 开发所需的工具,比如说解释器(java)、编译器(javac)、文档生成器(javadoc)等等。
JRE(Java Runtime Environment)是用于运行 Java 应用程序的软件环境。也就是说,如果只想运行 Java 程序而不需要开发 Java 程序的话,只需要安装 JRE 就可以了。
JVM (Java Virtual Machine) ,也就是 Java 虚拟机,由一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域等组成,屏蔽了不同操作系统(macOS、Windows、Linux)的差异性,使得 Java 能够“一次编译,到处运行”。
==源代码\字节码 java是编译还是解释==
Java 的第一道工序是通过 javac 命令把 Java 源码编译成字节码。
之后,我们可以通过 java 命令运行字节码(比如说 java Hello),此时就有 2 种处理方式了。
- 1、字节码由 JVM 逐条解释执行。
- 2、部分字节码可能由 JIT(即时编译编译为机器指令直接执行。
①、逐条解释执行:
逐条解释执行是 Java 虚拟机的基本执行模式。在这种模式下,Java 虚拟机会逐条读取字节码文件中的指令,并将其解释为对应的底层操作。解释执行的优点是实现简单,启动速度较快,但由于每次执行都需要对字节码进行解释,因此执行效率相对较低。
总结一下逐条解释执行的特点:
- 实现简单
- 启动速度较快
- 执行效率较低
②、JIT 即时编译:
为了提高 Java 程序的执行效率,Java 虚拟机引入了即时编译(JIT,Just-In-Time Compilation)技术。在 JIT 模式下,Java 虚拟机会在运行时将频繁执行的字节码编译为本地机器码,这样就可以直接在硬件上运行,而不需要再次解释。这样做的结果是显著提高了程序的执行速度。需要注意的是,JIT 编译器并不会编译所有的字节码,而是根据一定的策略,仅编译被频繁调用的代码段(热点代码)。
总结一下 JIT 即时编译的特点:
- 提高执行效率
- 编译热点代码
- 动态优化
实际上,现代 Java 虚拟机(如 HotSpot)通常会结合这两种执行方式,即解释执行和 JIT 即时编译。在程序运行初期,Java 虚拟机会采用解释执行,以减少启动时间。随着程序的运行,Java 虚拟机会识别出热点代码并使用 JIT 编译器将其编译为本地机器码,从而提高程序的执行效率。这种结合策略称为混合模式。
==Java数据类型==
基本数据类型

int和char转换
int->char
强制类型转换
int value_int = 65; char value_char = (char) value_int;可以使用
Character.forDigit()方法将整型 int 转换为字符 char,参数radix为基数,十进制为10,十六进制为16char value_char = Character.forDigit(value_int , radix);可以使用int的包装器类型Integer的
toString()方法+String的charAt()方法转成charchar value_char = Integer.toString(value_int).charAt(0);
char->int
直接赋值
int a = 'a';数字可以使用
Character.digit()方法或使用Character.digit()方法或- '0'方法字符’0’的编码值是48,字符’1’的编码值是49,依此类推,字符’9’的编码值是57
int a = Character.getNumericValue('1'); int b = Character.digit('1', 10); int c= '1' - '0';
包装类
基本数据类型vs引用类型
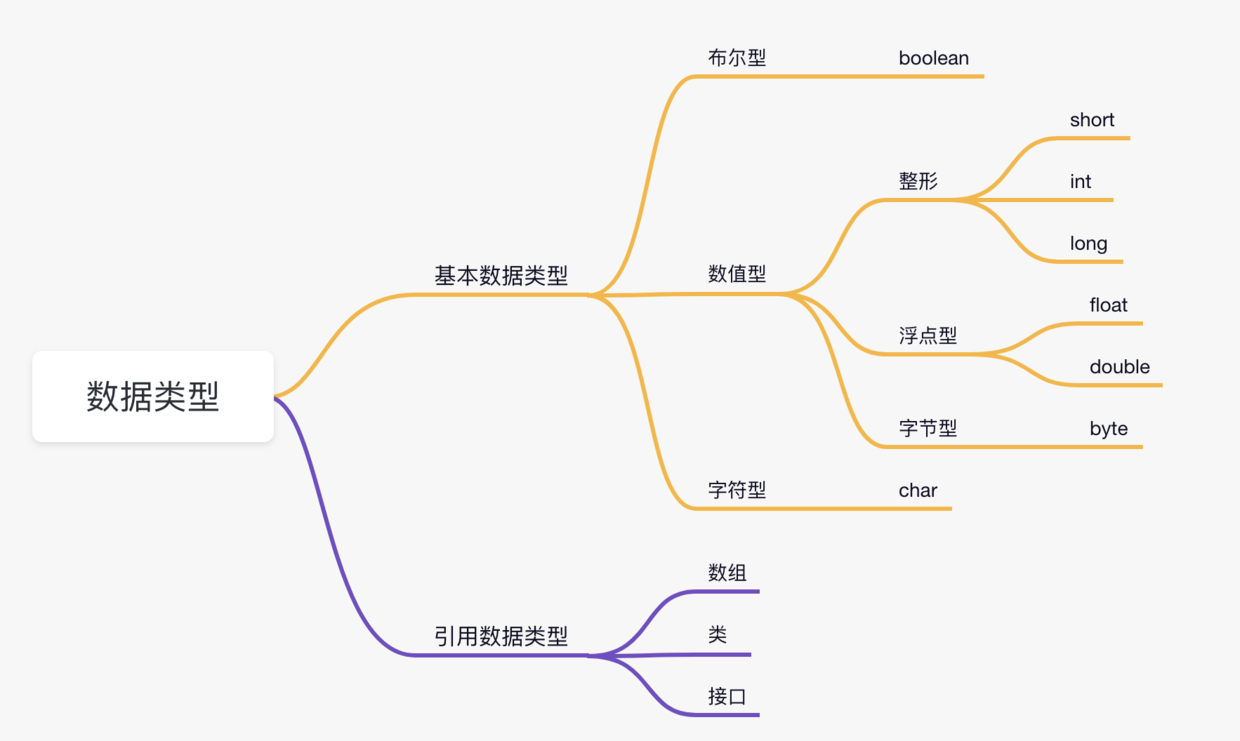
基本数据类型:
- 变量名指向具体的数值
- 基本数据类型存储在栈上
引用数据类型:
- 变量名指向的是存储对象的内存地址,在栈上
- 内存地址指向的对象存储在堆上
==数据类型转换==
自动类型转换
自动类型转换(自动类型提升)是 Java 编译器在不需要显式转换的情况下,将一种基本数据类型自动转换为另一种基本数据类型的过程。这种转换通常发生在表达式求值期间,当不同类型的数据需要相互兼容时。自动类型转换遵循以下规则:
- 如果任一操作数是double类型,其他操作数将被转换为double类型
- 否则,如果任一操作数是float类型,其他操作数将被转换为float类型
- 否则,如果任一操作数是long类型,其他操作数将被转换为long类型
- 否则,所有操作数将被转换为int类型
byte -> short -> int -> long -> float -> double
char -> int -> long -> float -> double强制类型转换
强制类型转换是 Java 中将一种数据类型显式转换为另一种数据类型的过程。与自动类型转换不同,强制类型转换需要程序员显式地指定要执行的转换。强制类型转换在以下情况中可能需要:
- 将较大的数据类型转换为较小的数据类型。
- 将浮点数转换为整数。
- 将字符类型转换为数值类型。
需要注意的是,强制类型转换可能会导致数据丢失或精度降低
==基本数据类型缓存池(IntegerCache)==
基本数据类型的包装类除了 Float和Double之外,其他六个包装器类(Byte、Short、Integer、Long、Character、Boolean)都有常量缓存池。
- Byte:-128~127,也就是所有的 byte 值
- Short:-128~127
- Long:-128~127
- Character:\u0000 - \u007F
- Boolean: true 和 false
拿Integer来举例子,Integer 类内部中内置了256个Integer 类型的缓存数据,当使用的数据范围在 -128~127 之间时,会直接返回常量池中数据的引用,而不是创建对象,超过这个范围时会创建新的对象。
在Java中,针对一些基本数据类型(如Integer、Long、Boolean等),Java 会在程序启动时创建一些常用的对象并缓存在内存中,以提高程序性能和节省内存开销。这些常用对象被缓存在一个固定范围内,超出这个范围的值会被重新创建新的对象。
使用数据类型缓存池可以有效提高程序的性能和节省内存开销,但需要注意的是,在特定的业务场景下,缓存池可能会带来一些问题,例如缓存池中的对象被不同的线程同时修改,导致数据错误等问题。因此,在实际开发中,需要根据具体的业务需求来决定是否使用数据类型缓存池。
==运算符==
浮点数除以0的时候,结果为Infinity或者NaN
整数除以0的时候,会抛出异常
数组&字符串
==数组==
数组是一个对象,它包含了一组固定数量的元素,并且这些元素的类型是相同的。数组会按照索引的方式将元素放在指定的位置上,意味着我们可以通过索引来访问这些元素。在Java中,索引是从0开始的。
数组也是一个对象,但Java中并未明确定义这样一个类
数组的声明与初始化
可变参数与数组
本质上,可变参数就是通过数组实现的
数组与 List
把数组转成List
遍历数组,创建List添加元素
Arrays类的
asList()方法List<Integer> aList = Arrays.asList(anArray); // Integer数组 List<Integer> aList1 = Arrays.asList(1, 2, 3, 4, 5);stream流
List<Integer> aList = Arrays.stream(anArray).boxed().collect(Collectors.toList());
Arrays.asList方法返回的ArrayList并不是java.util.ArrayList,它其实是Arrays类的一个内部类
如果需要添加元素或者删除元素的话,需要把它转成java.util.ArrayList
new ArrayList<>(Arrays.asList(anArray));数组的排序与查找
如果想对数组进行排序的话,可以使用Arrays 类提供的sort()方法。
- 基本数据类型按照升序排列
- 实现了Comparable接口的对象按照
compareTo()的排序
查找
- 遍历
- Arrays.binarySearch()
数组的复制
遍历复制
Arrays.copyOfRange()方法用来复制数组。底层调用的是System.arraycopy()方法,这个方法是一个native方法,它是用 C/C++ 实现的,效率非常高
数组越界
==二维数组==
二维数组是一种数据类型,可以存储多行和多列的数据。它由一系列的行和列组成,每个元素都可以通过一个行索引和列索引来访问。使用二维数组可以有效地存储和处理表格数据,如矩阵、图像、地图等
==数组打印==
Arrays.asList(cmowers).stream().forEach(s -> System.out.println(s));
Stream.of(cmowers).forEach(System.out::println);
Arrays.stream(cmowers).forEach(System.out::println);
for(int i = 0; i < cmowers.length; i++){
System.out.println(cmowers[i]);
}
for (String s : cmowers) {
System.out.println(s);
}
System.out.println(Arrays.toString(cmowers));
System.out.println(Arrays.deepToString(deepArray));==字符串源码==
String 类的声明
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
}- String类是final的,意味着它不能被子类继承
- String类实现了Serializable接口,意味着它可以序列化
- String类实现了Comparable接口,意味着最好不用‘==’比较两个字符串是否相等,而应该用
compareTo()方法比较 - String 和 StringBuffer、StringBuilder一样,都实现了CharSequence接口
String底层为什么由char数组优化为byte数组
// jdk8
private final char value[];
// jdk11
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
@Stable
private final byte[] value;
private final byte coder;
private int hash;
}- 节省字符串占用的内存空间,内存占用减少GC次数也会减少
- 从
char[]到byte[],中文是两个字节,纯英文是一个字节,在此之前,中文是两个字节,英文也是两个字节
String类的hashCode方法
每一个字符串都会有一个hash值,哈希值在很大概率是不会重复的,因此String很适合来作为HashMap的键值
// 31倍hash法
private int hash; // 缓存字符串的哈希码
public int hashCode() {
int h = hash; // 从缓存中获取哈希码
// 如果哈希码未被计算过(即为 0)且字符串不为空,则计算哈希码
if (h == 0 && value.length > 0) {
char val[] = value; // 获取字符串的字符数组
// 遍历字符串的每个字符来计算哈希码
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i]; // 使用 31 作为乘法因子
}
hash = h; // 缓存计算后的哈希码
}
return h; // 返回哈希码
}String类的substring方法
public String substring(int beginIndex) {
// 检查起始索引是否小于 0,如果是,则抛出 StringIndexOutOfBoundsException 异常
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
// 计算子字符串的长度
int subLen = value.length - beginIndex;
// 检查子字符串长度是否为负数,如果是,则抛出 StringIndexOutOfBoundsException 异常
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
// 如果起始索引为 0,则返回原字符串;否则,创建并返回新的字符串
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}String类的indexOf方法
/*
* 查找字符数组 target 在字符数组 source 中第一次出现的位置。
* sourceOffset 和 sourceCount 参数指定 source 数组中要搜索的范围,
* targetOffset 和 targetCount 参数指定 target 数组中要搜索的范围,
* fromIndex 参数指定开始搜索的位置。
* 如果找到了 target 数组,则返回它在 source 数组中的位置索引(从0开始),
* 否则返回-1。
*/
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 如果开始搜索的位置已经超出 source 数组的范围,则直接返回-1(如果 target 数组为空,则返回 sourceCount)
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
// 如果开始搜索的位置小于0,则从0开始搜索
if (fromIndex < 0) {
fromIndex = 0;
}
// 如果 target 数组为空,则直接返回开始搜索的位置
if (targetCount == 0) {
return fromIndex;
}
// 查找 target 数组的第一个字符在 source 数组中的位置
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
// 循环查找 target 数组在 source 数组中的位置
for (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
// 如果 source 数组中当前位置的字符不是 target 数组的第一个字符,则在 source 数组中继续查找 target 数组的第一个字符
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
// 如果在 source 数组中找到了 target 数组的第一个字符,则继续查找 target 数组的剩余部分是否匹配
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
// 如果 target 数组全部匹配,则返回在 source 数组中的位置索引
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
// 没有找到 target 数组,则返回-1
return -1;
}String类的其他方法
length()用于返回字符串长度isEmpty()用于判断字符串是否为空charAt()用于返回指定索引处的字符valueOf()用于将其他类型的数据转换为字符串valueOf方法背后其实调用的是包装器类的toString方法,比如整数转为字符串调用的是Integer类的 toString方法
public static String valueOf(int i) { return Integer.toString(i); }
trim()去除字符串开头和结尾的空格split()将字符串按照特定符号分隔成单词数组concat()方法用于拼接字符串replace()替换方法intern()会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
==为什么Java字符串不可变?==
String 对象一旦被创建后就固定不变了,对 String对象的任何修改(截取、拼接、替换等)都不会影响到原来的字符串对象,都会生成新的字符串对象。原来的字符串对象并没有发生改变
- 可以保证String对象的安全性,避免被篡改。毕竟像密码这种隐私信息一般就是用字符串存储的
- 保证哈希值不会频繁变更。毕竟要经常作为哈希表的键值,经常变更的话,哈希表的性能就会很差劲。在String类中,哈希值是在第一次计算时缓存的,后续对该哈希值的请求将直接使用缓存值。这有助于提高哈希表等数据结构的性能。
- 可以实现字符串常量池,Java 会将相同内容的字符串存储在字符串常量池中。这样,具有相同内容的字符串变量可以指向同一个String对象,节省内存空间。
==Java字符串双引号 vs new对象声明==
在JAVA语言中有基本类型和一种比较特殊的类型String。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个JAVA系统级别提供的缓存。
8种基本类型的常量池都是系统协调的,String类型的常量池比较特殊
- 直接使用双引号声明出来的
String对象会直接存储在常量池中。 - 如果不是用双引号声明的
String对象,可以使用String提供的intern方法。intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中
==Java字符串常量池==

在 Java 中,栈上存储的是基本数据类型的变量和对象的引用,而对象本身则存储在堆上。
先在字符串常量池中创建对象,然后再在堆上创建
字符串常量池的作用
由于字符串的使用频率实在是太高了,所以Java虚拟机为了提高性能和减少内存开销,在创建字符串对象的时候进行了一些优化,特意为字符串开辟了一块空间——也就是字符串常量池。
字符串常量池在内存中的位置

Java 7之前
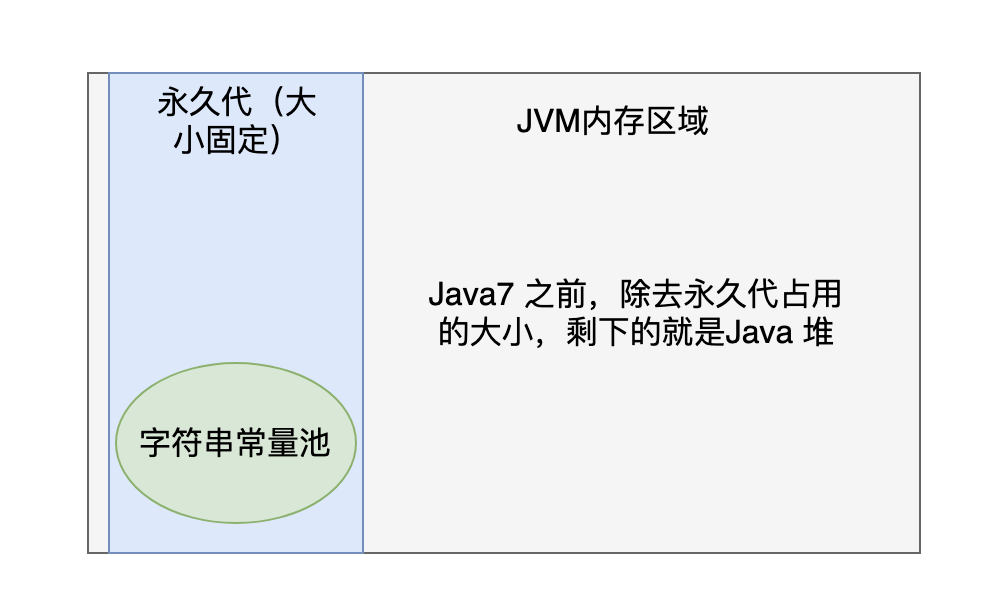
- 在Java 7之前,字符串常量池位于永久代(Permanent Generation)的内存区域中,主要用来存储一些字符串常量(静态数据的一种)。永久代是Java堆(Java Heap)的一部分,用于存储类信息、方法信息、常量池信息等静态数据。而Java堆是JVM中存储对象实例和数组的内存区域,也就是说,永久代是Java堆的一个子区域
Java 7

- 永久代的大小是有限的,并且很难准确地确定一个应用程序需要多少永久代空间。从Java 7开始,为了解决永久代空间不足的问题,将字符串常量池从永久代中移动到堆中。这个改变也是为了更好地支持动态语言的运行时特性。
Java 8
- 到了Java 8,永久代(PermGen)被取消,由元空间(Metaspace)取代。元空间是一块本机内存区域,和JVM 内存区域是分开的。不过,元空间的作用依然和之前的永久代一样,用于存储类信息、方法信息、常量池信息等静态数据。
- 元空间具有一些优点:
- 不会导致OutOfMemoryError错误,因为元空间的大小可以动态调整。
- 元空间使用本机内存,而不是JVM堆内存,这可以避免堆内存的碎片化问题。
- 元空间中的垃圾收集与堆中的垃圾收集是分离的,这可以避免应用程序在运行过程中因为进行类加载和卸载而频繁地触发Full GC。
方法区、永久代、元空间
- 方法区是Java虚拟机规范中的一个概念
- 永久代和元空间是HotSpot虚拟机中对方法区的不同实现
- 永久代是放在运行时数据区中的,所以它的大小受到Java虚拟机本身大小的限制
- 元空间是直接放在内存中的,所以只受本机可用内存的限制
详解String.intern()方法
==StringBuilder和StringBuffer==
StringBuffer操作字符串的方法加了synchronized 关键字进行了同步,主要是考虑到多线程环境下的安全问题,所以如果在非多线程环境下,执行效率就会比较低,因为加了没必要的锁。
StringBuilder在单线程环境下使用,效率高。如果在多线程环境下修改字符串,可以使用ThreadLocal来避免多线程冲突
StringBuilder的内部实现
// StringBuilder 的 toString 方法。count 是一个 int 类型的变量,表示字符序列的长度。
public String toString() {
return new String(value, 0, count);
}
// value 是一个 char 类型的数组
char[] value;
// StringBuilder 对象创建时,会为 value 分配一定的内存空间(初始容量 16),用于存储字符串
public StringBuilder() {
super(16);
}
// append(String str) 方法会检查当前字符序列中的字符是否够用,如果不够用则会进行扩容,并将指定字符串追加到字符序列的末尾。
public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
// ensureCapacityInternal(int minimumCapacity) 方法用于确保当前字符序列的容量至少等于指定的最小容量 minimumCapacity。如果当前容量小于指定的容量,就会为字符序列分配一个新的内部数组。
private void ensureCapacityInternal(int minimumCapacity) {
// 不够用了,扩容
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
void expandCapacity(int minimumCapacity) {
// 扩容策略:新容量为旧容量的两倍加上 2
int newCapacity = value.length * 2 + 2;
// 如果新容量小于指定的最小容量,则新容量为指定的最小容量
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
// 如果新容量小于 0,则新容量为 Integer.MAX_VALUE
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
// 将字符序列的容量扩容到新容量的大小
value = Arrays.copyOf(value, newCapacity);
}StringBuilder的reverse方法
public AbstractStringBuilder reverse() {
int n = count - 1; // 字符序列的最后一个字符的索引
// 遍历字符串的前半部分
for (int j = (n-1) >> 1; j >= 0; j--) {
int k = n - j; // 计算相对于 j 对称的字符的索引
char cj = value[j]; // 获取当前位置的字符
char ck = value[k]; // 获取对称位置的字符
value[j] = ck; // 交换字符
value[k] = cj; // 交换字符
}
return this; // 返回反转后的字符串构建器对象
}==字符串相等判断==
==操作符 用于比较地址.equals()方法 用于比较内容
// Object的equals 源码
public boolean equals(Object obj) {
return (this == obj);
}Object 类的.equals()方法默认采用的是==操作符进行比较。假如子类没有重写该方法的话,那么==操作符和 .equals()方法完全一样
// String类的equals源码
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String aString = (String)anObject;
if (coder() == aString.coder()) {
return isLatin1() ? StringLatin1.equals(value, aString.value)
: StringUTF16.equals(value, aString.value);
}
}
return false;
}字符串相等判断其他方法
Objects.equals()
- ==不需要判空==
public static boolean equals(Object a, Object b) { return (a == b) || (a != null && a.equals(b)); } // 直接使用 a.equals(b),则需要在调用之前对a进行判空,否则可能抛出空指针 java.lang.NullPointerExceptionString 类的
.contentEquals()- ==可以将字符串与任何字符序列(StringBuffer、StringBuilder、String、CharSequence)比较==
==字符串拼接==
- +号操作符
- 本质上是new StringBuilder对象进行append操作
- StringBuilder.append()
- 判空
- 获取长度
- 判断扩容
- 拼接复制
- 更新数组长度count
- String.concat()
- 判断待拼接长度是否为0,是返回当前字符串
- 复制当前字符串
- 复制待拼接字符串,返回新字符串对象
- String.join()
- 第一个参数为字符串连接符
- 新建一个StringJoiner对象,通过for-each循环把可变参数添加进来,最后调用
toString()返回String
- StringUtils.join()
- 内部使用的仍然是 StringBuilder。该方法不用担心 NullPointerException
concat()方法在遇到字符串为null的时候,会抛出NullPointerException
而“+”号操作符会把 null 当做是“null”字符串来处理。
如果拼接的字符串是一个空字符串(""),那么concat的效率要更高一点,毕竟不需要new StringBuilder对象。
如果拼接的字符串非常多,concat()的效率就会下降,因为创建的字符串对象越来越多
==字符串拆分==
面向对象编程
==类和对象==
面向过程和面向对象
- 状态+行为+标识=对象,每个对象在内存中都会有一个唯一的地址
- 对象具有接口
- 访问权限修饰符
- 组合代表的关系是has-a的关系
- 继承是is-a或is-like-a的关系
类
一个类可以包含:
- 字段(Filed)
- 方法(Method)
- 构造方法(Constructor)
成员变量——在类内部但在方法外部,方法内部的叫临时变量。
成员变量有时也叫做实例变量,在编译时不占用内存空间,在运行时获取内存,也就是说,只有在对象实例化后,字段才会获取到内存,这也正是它被称作“实例”变量的原因
new一个对象
所有对象在创建的时候都会在堆内存中分配空间
匿名对象意味着没有引用变量,它只能在创建的时候被使用一次
初始化对象
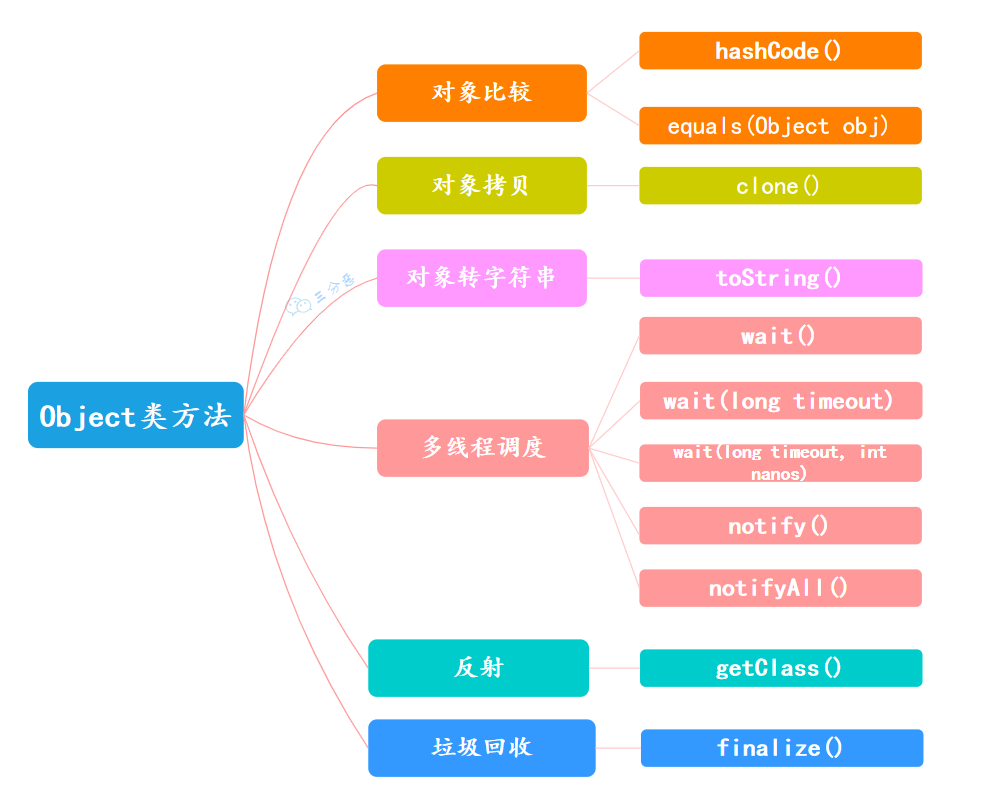
关于Object类
==包==
包没有父子关系。java.util和java.util.zip是不同的包,两者没有任何继承关系
Java内建的package机制是为了避免class命名冲突;
JDK的核心类使用java.lang包,编译器会自动导入
没有定义包名的class,它使用的是默认包,非常容易引起名字冲突,因此,不推荐不写包名的做法。
包的作用域
导入包
- 使用完整类名
import语句import static语法,可以导入一个类的静态字段和静态方法
Java 编译器最终编译出的.class文件只使用 完整类名,因此,在代码中,当编译器遇到一个class名称时:
- 如果是完整类名,就直接根据完整类名查找这个
class; - 如果是简单类名,按下面的顺序依次查找:
- 查找当前
package是否存在这个class; - 查找
import的包是否包含这个class; - 查找
java.lang包是否包含这个class
- 查找当前
默认自动import当前package的其他class;
默认自动import java.lang.*
包的最佳实践
- 使用倒置的域名来确保唯一性
==变量==
局部变量
- 在方法体内声明的变量,只能在该方法内使用
- 局部变量在方法、构造方法、或者语句块被执行的时候创建,当它们执行完成后,将会被销毁。
- 访问修饰符不能用于局部变量。
- 局部变量只在声明它的方法、构造方法或者语句块中可见。
- 局部变量是在栈上分配的。
- 局部变量没有默认值,所以局部变量被声明后,必须经过初始化,才可以使用。
成员变量
- 在类内部但在方法体外声明的变量称为成员变量,或者实例变量,或者字段。该变量只能通过类的实例(对象)来访问
- 成员变量在对象创建的时候创建,在对象被销毁的时候销毁
- 成员变量可以声明在使用前或者使用后
- 访问修饰符可以修饰成员变量
- 成员变量具有默认值。数值型变量的默认值是0,布尔型变量的默认值是false,引用类型变量的默认值是null
静态变量
- 通过static关键字声明的变量被称为静态变量(类变量),它可以直接被类访问
- 无论一个类创建了多少个对象,类只拥有静态变量的一份拷贝
- 静态变量在程序开始时创建,在程序结束时销毁
- 静态变量储存在静态存储区
- 静态变量还可以在静态语句块中初始化
常量
==方法==
声明
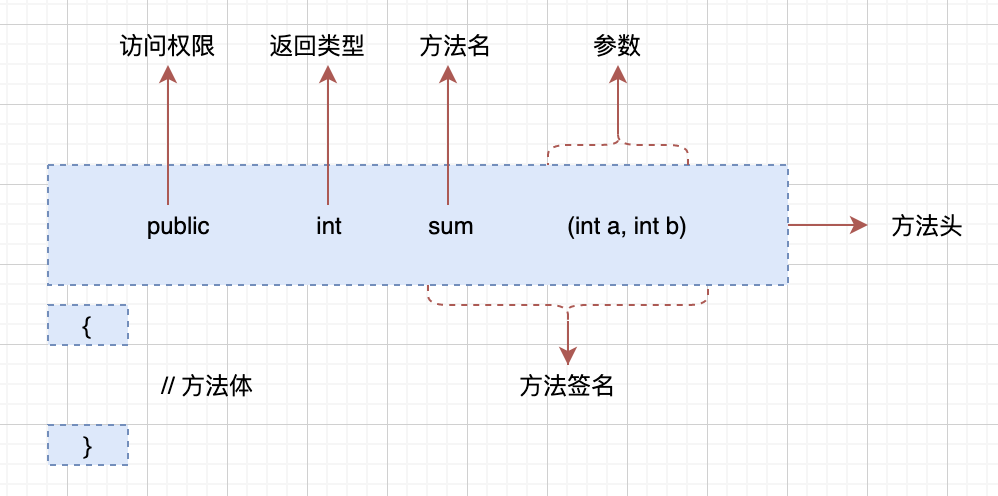
访问权限:指定方法的可见性。Java提供了四种访问权限修饰符
public:该方法可以被所有类访问。
private:该方法只能在定义它的类中访问。
protected:该方法可以被同一个包中的类,或者不同包中的子类访问。
default:package-private 的,意味着该方法只能被同一个包中的类可见。
返回类型:方法返回的数据类型,可以是基本数据类型、对象和集合,如果不需要返回数据,则使用void关键字。
方法签名:每一个方法都有一个签名,包括方法名和参数。
- 方法名
- 参数:参数类型和参数名
方法体
实例方法 静态方法
没有使用static关键字修饰,但在类中声明的方法被称为实例方法,在调用实例方法之前,必须创建类的对象
有static关键字修饰的方法就叫做静态方法
抽象方法
没有方法体的方法被称为抽象方法,它总是在抽象类中声明。这意味着如果类有抽象方法的话,这个类就必须是抽象的。可以使用abstract关键字创建抽象方法和抽象类。当一个类继承了抽象类后,就必须重写抽象方法
==可变参数==
可变参数是Java 1.5的时候引入的功能,它允许方法使用任意多个、类型相同(is-a)的值作为参数
尽量不要使用可变参数,如果要用的话,可变参数必须要在参数列表的最后一位
使用可变参数时,实际上先创建一个数组,该数组大小是可变参数的个数,然后将参数放入数组中,将数组传递给被调用方法。
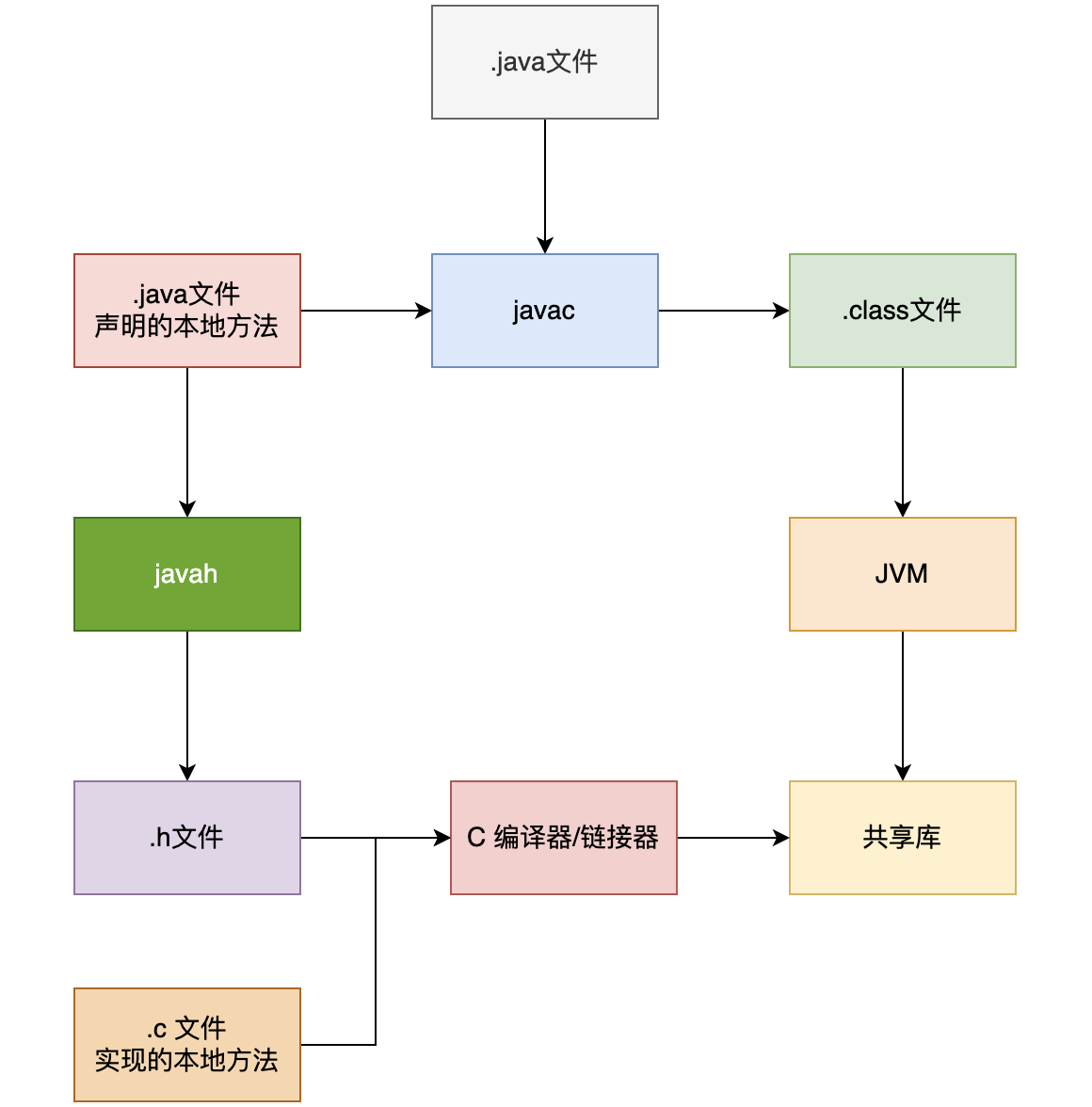
==native方法==
用native关键词修饰的方法,多数情况下不需要用Java语言实现
JNI:Java Native Interface
场景
- 标准的Java类库不支持。
- 已经用另一种语言编写了一个类库,用Java代码调用
- 某些运行次数特别多的方法,为了加快性能,需要用更接近硬件的语言(比如汇编)编写
通过JNI,我们就可以通过Java程序(代码)调用到操作系统相关的技术实现的库函数,从而与其他技术和系统交互;同时其他技术和系统也可以通过JNI提供的相应原生接口调用Java应用系统内部实现的功能
JNI的缺点:
- 程序不再跨平台。要想跨平台,必须在不同的系统环境下重新编译本地语言部分。
- 程序不再是绝对安全的,本地代码的不当使用可能导致整个程序崩溃。一个通用规则是,应该让本地方法集中在少数几个类当中。这样就降低了Java和C/C++之间的耦合性
JNI调用C的流程图
native关键字
native语法:
- 修饰方法的位置必须在返回类型之前,和其余的方法控制符前后关系不受限制。
- 不能用abstract修饰,也没有方法体,也没有左右大括号。
- 返回值可以是任意类型
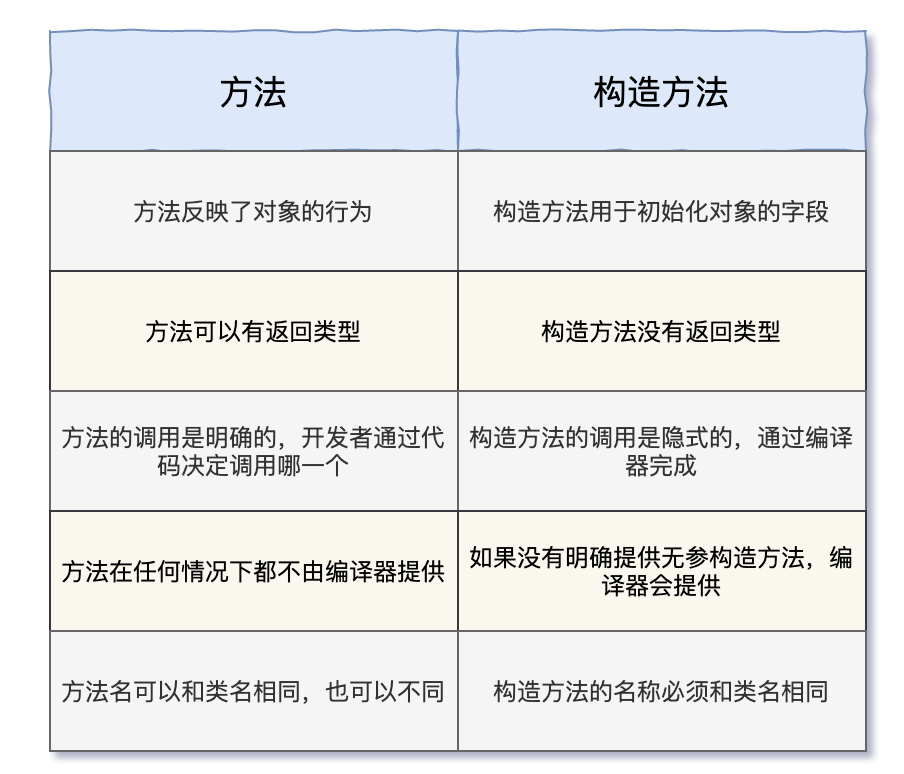
==构造方法==
构造方法是一种特殊的方法,当一个类被实例化的时候,就会调用构造方法。只有在构造方法被调用的时候,对象才会被分配内存空间。每次使用new关键字创建对象的时候,构造方法至少会被调用一次
规则
- 构造方法的名字必须和类名一样;
- 构造方法没有返回类型,包括 void;
- 构造方法不能是抽象的(abstract)、静态的(static)、最终的(final)、同步的(synchronized)
- 由于构造方法不能被子类继承,所以用final和abstract关键字修饰没有意义
- 构造方法用于初始化一个对象,所以用static关键字修饰没有意义
- 多个线程不会同时创建内存地址相同的同一个对象,所以用synchronized关键字修饰没有必要
构造方法和方法的区别
复制对象
- 通过构造方法
- 通过对象的值
- 通过Object类的
clone()方法- 通过
clone()方法复制对象的时候,必须先实现Cloneable接口的clone()方法,然后再调用clone()方法
- 通过
==访问权限修饰符==
在 Java 中,提供了四种访问权限控制:
- 默认访问权限(包访问权限)
- public
- private
- protected
类只可以用默认访问权限和public修饰。但变量和方法则都可以修饰。
Java中的包主要是为了防止类文件命名冲突以及方便进行代码组织和管理;
对于一个Java源代码文件,如果存在public类的话,只能有一个public类,且此时源代码文件的名称必须和public类的名称完全相同。如果存在其他类,这些类在包外是不可见的。如果源代码文件没有public类,则源代码文件的名称可以随意命名。
==代码初始化块==
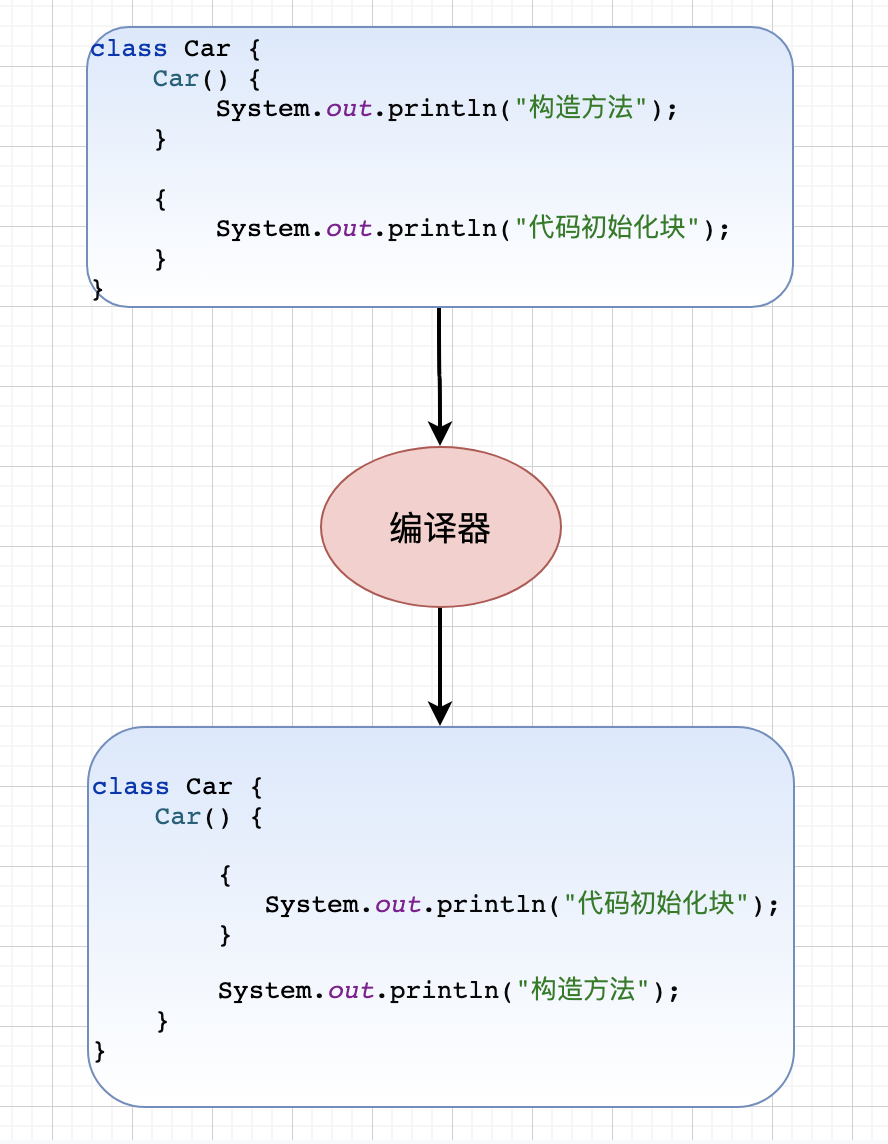
- 类实例化的时候执行代码初始化块;
- 实际上,代码初始化块是放在构造方法中执行的,只不过比较靠前;
- 代码初始化块里的执行顺序是从前到后的。
- 在默认情况下,子类的构造方法在执行的时候会主动去调用父类的构造方法。显示:父初始化>父构造>子初始化>子构造
- 静态初始化块在类加载时执行,只会执行一次,并且优先于实例初始化块和构造方法的执行;实例初始化块在每次创建对象时执行,在构造方法之前执行
==抽象类==
抽象类命名规范 - 抽象类命名要使用Abstract或Base开头
抽象类不能实例化
抽象类中的抽象方法没有方法体
如果一个类定义了一个或多个抽象方法,那么这个类必须是抽象类
抽象类中既可以定义抽象方法,也可以定义普通方法
抽象类的子类必须给出父类中的抽象方法的具体实现,除非该子类也是抽象类
抽象类使用场景
- 一些通用的功能被多个子类复用的时候
- 需要在抽象类中定义好API,然后在子类中扩展实现的时候就可以使用抽象类
==接口==
接口是隐式抽象的,所以声明时没有必要使用
abstract关键字;接口的每个方法都是隐式抽象的,所以同样不需要使用
abstract关键字;接口中的方法都是隐式
public的接口通过interface关键字来定义,它可以包含一些常量和方法
接口中定义的变量会在编译的时候自动加上
public static final修饰符没有使用
private、default或者static关键字修饰的方法是隐式抽象的从Java 8开始,接口中允许有静态方法。静态方法无法由(实现了该接口的)类的对象调用,它只能通过接口名来调用
从Java 8开始接口中允许定义
default方法。始终由一个代码块组成,为实现该接口而不覆盖该方法的类提供默认实现。既然要提供默认实现,就要有方法体接口不允许直接实例化
接口可以是空的
不要在定义接口的时候使用final关键字
接口的抽象方法不能是private、protected或者final
接口的变量是隐式
public static final(常量),所以其值无法改变
接口的作用
- 使某些实现类具有我们想要的功能
- Java原则上只支持单一继承,但通过接口可以实现多重继承的目的
- 实现多态
- 多态存在的3个前提
- 要有继承关系
- 子类要重写父类的方法
- 父类引用指向子类对象
- 多态存在的3个前提
接口的三种模式
策略模式
- 策略模式的思想是,针对一组算法,将每一种算法封装到具有共同接口的实现类中,接口的设计者可以在不影响调用者的情况下对算法做出改变
适配器模式
- 适配器模式的思想是,针对调用者的需求对原有的接口进行转接。如果我们只需要对其中一个方法进行实现的话,就可以使用一个抽象类作为中间件,即适配器(AdapterCoach),用这个抽象类实现接口,并对抽象类中的方法置空(方法体只有一对花括号),这时候,新类就可以绕过接口,继承抽象类,我们就可以只对需要的方法进行覆盖,而不是接口中的所有方法。
工厂模式
抽象类和接口的区别
语法层面上
抽象类可以包含具体方法的实现;
在接口中,方法默认是public abstract的,但从Java 8开始,接口也可以包含有实现的默认方法和静态方法。
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
接口中不能含有静态代码块,而抽象类可以有静态代码块;
一个类只能继承一个抽象类,而一个类却可以实现多个接口
设计层面上
抽象类是对一种事物的抽象,即对类抽象,继承抽象类的子类和抽象类本身是一种
is-a的关系。而接口是对行为的抽象。接口和类之间并没有很强的关联关系
抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计
==内部类==
可以将一个类定义在另外一个类里面或者一个方法里面,这样的类叫做内部类
成员内部类
内部类可以随意访问外部类的成员,但外部类想要访问内部类的成员,必须先创建一个成员内部类的对象,再通过对象访问
如果想要在静态方法中访问成员内部类的时候,就必须先得创建一个外部类的对象,因为内部类是依附于外部类的
这种创建内部类的方式在实际开发中并不常用,因为内部类和外部类紧紧地绑定在一起,使用起来非常不便
局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,所以局部内部类的生命周期仅限于作用域内
局部内部类就好像一个局部变量一样,它是不能被权限修饰符修饰的
匿名内部类
匿名内部类就好像一个方法的参数一样,用完就没
匿名内部类是唯一一种没有构造方法的类,就像是直接通过new关键字创建出来的一个对象。名字是借用的外部类$1
匿名内部类的作用主要是用来继承其他类或者实现接口,并不需要增加额外的方法,方便对继承的方法进行实现或者重写
静态内部类
静态内部类和成员内部类类似,只是多了一个static关键字
由于static关键字的存在,静态内部类是不允许访问外部类中非static的变量和方法的
使用内部类
- 每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响.可以这样说,接口只是解决了部分问题,而内部类使得多重继承的解决方案变得更加完整。
- 1、内部类可以使用多个实例,每个实例都有自己的状态信息,并且与其他外围对象的信息相互独立。
- 2、在单个外部类中,可以让多个内部类以不同的方式实现同一个接口,或者继承同一个类。
- 3、创建内部类对象的时刻并不依赖于外部类对象的创建。
- 4、内部类并没有令人迷惑的“is-a”关系,内部类就是一个独立的实体。
- 5、内部类提供了更好的封装,除了该外围类,其他类都不能访问。
==封装继承多态==
封装
信息隐藏,是指利用抽象将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。
使用封装有4大好处:
- 1、良好的封装能够减少耦合。
- 2、类内部的结构可以自由修改。
- 3、可以对成员进行更精确的控制。
- 4、隐藏信息,实现细节。
继承
子类继承父类的属性和方法,使得子类对象(实例)具有父类的属性和方法
使用继承不仅大大的减少了代码量,也使得代码结构更加清晰可见。
==继承的分类==
- 单继承
- 多继承(Java虽然不支持多继承,但是Java有三种实现多继承效果的方式)
- 内部类 - 可以继承一个与外部类无关的类,保证了内部类的独立性 -
- 多层继承 - 子类拥有所有被继承类的属性和方法
- 实现接口 - 满足多继承使用需求的最好方式
继承的主要内容就是子类继承父类,并重写父类的方法
子类继承父类就拥有父类的非私有的属性和方法。父类的构造方法不能被继承,子类的构造过程必须调用其父类的构造方法
Java虚拟机构造子类对象前会先构造父类对象,父类对象构造完成之后再来构造子类特有的属性,这被称为内存叠加
如果子类的构造方法中没有显示地调用父类构造方法,则系统默认调用父类无参数的构造方法
==继承与修饰符==
- 访问修饰符
- Java子类重写继承方法时不可以降低访问权限,子类继承父类的访问修饰符作用域不能比父类小,需要更加开放
- 子类方法的异常不可大于父类对应方法抛出异常范围,子类抛出的异常必须是父类异常或父类异常的子异常
- 非访问修饰符
==Object类和转型==
如果一个类没有显式声明它的父类(即没有写 extends xx),那么默认这个类的父类就是Object类,任何类都可以使用 Object类的方法,创建的类也可和Object进行向上、向下转型
==子父类初始化顺序==
在Java继承中,父子类初始化先后顺序为:
- 父类中静态成员变量和静态代码块
- 子类中静态成员变量和静态代码块
- 父类中普通成员变量和代码块,父类的构造方法
- 子类中普通成员变量和代码块,子类的构造方法
多态
在面向对象编程中,同一个类的对象在不同情况下表现出来的不同行为和状态
多态的前提条件有三个:
- 子类继承父类
- 子类重写父类的方法
- 父类引用指向子类的对象
在运行时根据对象的类型进行后期绑定.编译器在编译阶段并不知道对象的类型,但是Java方法调用机制能找到正确的方法体,然后执行,得到正确的结果
==this和super==
this
- 作为引用变量,指向当前对象
- 调用当前类的方法
this()可以调用当前类的构造方法.this()必须放在构造方法的第一行- this可以作为参数在方法中传递
- this可以作为参数在构造方法中传递
- this可以作为方法的返回值,返回当前类的对象
super
- 指向父类对象;
- 调用父类的方法;
super()可以调用父类的构造方法。在默认情况下,super()是可以省略的,编译器会主动去调用父类的构造方法。也就是说,子类即使不使用super()主动调用父类的构造方法,父类的构造方法仍然会先执行
==static==
方便在没有创建对象的情况下进行调用
==final==
==instanceof==
==不可变对象==
什么是不可变类
一个类的对象在通过构造方法创建后如果状态不会再被改变,那么它就是一个不可变(immutable)类。它的所有成员变量的赋值仅在构造方法中完成,不会提供任何setter方法供外部类去修改。
常见的不可变类 - String类
- 常量池的需要。减少JVM的内存开销,提高效率
- hashCode需要。String不可变作为哈希值,确保多次调用只返回同一个值
- 线程安全需要。可以在多个线程之间共享,不需要同步处理
不可变类必须满足的4个条件
确保类是final的,不允许被其他类继承*。
确保所有的成员变量(字段)是final的,只能在构造方法中初始化值,并且不会在随后被修改。
不要提供任何setter方法。
如果要修改类的状态,必须返回一个新的对象。
如果一个不可变类中包含了可变类的对象,那么就需要确保返回的是可变对象的副本
==方法重写和方法重载==
方法重写 Override
子类具有和父类一样的方法(参数相同、返回类型相同、方法名相同,但方法体可能不同)
重写时应当遵守的12条规则
- 只能重写继承过来的方法
- final、static的方法不能被重写
- 重写的方法必须有相同的参数列表
- 重写的方法必须返回相同的类型
- 重写的方法不能使用限制等级更严格的权限修饰符
- 重写后的方法不能抛出比父类中更高级别的异常
- 可以在子类中通过super关键字来调用父类中被重写的方法
- 构造方法不能被重写
- 如果一个类继承了抽象类,抽象类中的抽象方法必须在子类中被重写
- synchronized关键字对重写规则没有任何影响
- strictfp关键字对重写规则没有任何影响
方法重载 Overloading
一个类有多个名字相同但参数个数不同的方法
main()方法可以重载,但Java虚拟机在运行的时候只会调用String[]的main()方法由于可以通过改变参数类型的方式实现方法重载,当传递的参数没有找到匹配的方法时,就会发生隐式类型转换
==注解==
注解(Annotation)是在Java 1.5时引入的概念,同class和interface一样,也属于一种类型。注解提供了一系列数据用来装饰程序代码(类、方法、字段等),但是注解并不是所装饰代码的一部分,它对代码的运行效果没有直接影响,由编译器决定该执行哪些操作
注解的生命周期
- 注解的生命周期有3种策略,定义在RetentionPolicy枚举中
- SOURCE - 在源文件中有效,被编译器丢弃
- CLASS - 在编译器生成的字节码文件中有效,但在运行时会被处理类文件的JVM丢弃。
- RUNTIME - 在运行时有效。注解生命周期中最常用的一种策略,它允许程序通过反射的方式访问注解,并根据注解的定义执行相应的代码
注解的类型
注解的类型一共有11种,定义在ElementType枚举中
TYPE - 用于类、接口、注解、枚举
FIELD - 用于字段(类的成员变量),或者枚举常量
METHOD - 用于方法
PARAMETER - 用于普通方法或者构造方法的参数
CONSTRUCTOR - 用于构造方法
LOCAL_VARIABLE - 用于变量
ANNOTATION_TYPE - 用于注解
PACKAGE - 用于包
TYPE_PARAMETER - 用于泛型参数
TYPE_USE - 用于声明语句、泛型或者强制转换语句中的类型
MODULE - 用于模块
==枚举enum==
枚举(enum)是Java 1.5时引入的关键字。它表示一种特殊类型的类,继承自java.lang.Enum
EnumSet
- 一个专门针对枚举类型的Set接口的实现类
- 抽象类,创建时不能使用new关键字,提供许多静态工厂方法
noneOf()静态工厂方法创建了一个空的枚举类型的EnumSetallOf()静态工厂方法创建了一个包含所有枚举类型的EnumSet- 可以使用Set的一些方法
EnumMap
- 一个专门针对枚举类型的Map接口的实现类,它可以将枚举常量作为键来使用
- 非抽象类,创建时可以使用new关键字
- EnumMap的效率比HashMap还要高,可以直接通过数组下标(枚举的ordinal值)访问到元素
- 可以使用Map的一些方法
枚举实现单例
单例(Singleton)用来保证一个类仅有一个对象,并提供一个访问它的全局访问点,在一个进程中。因为这个类只有一个对象,所以就不能再使用
new关键字来创建新的对象传统实现 - volatile、synchronized关键字
public class Singleton { private volatile static Singleton singleton; private Singleton (){} public static Singleton getSingleton() { if (singleton == null) { synchronized (Singleton.class) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }枚举实现 - ==枚举默认实现了Serializable接口,因此 Java 虚拟机可以保证该类为单例==
public enum EasySingleton{ INSTANCE; }
集合框架(容器)
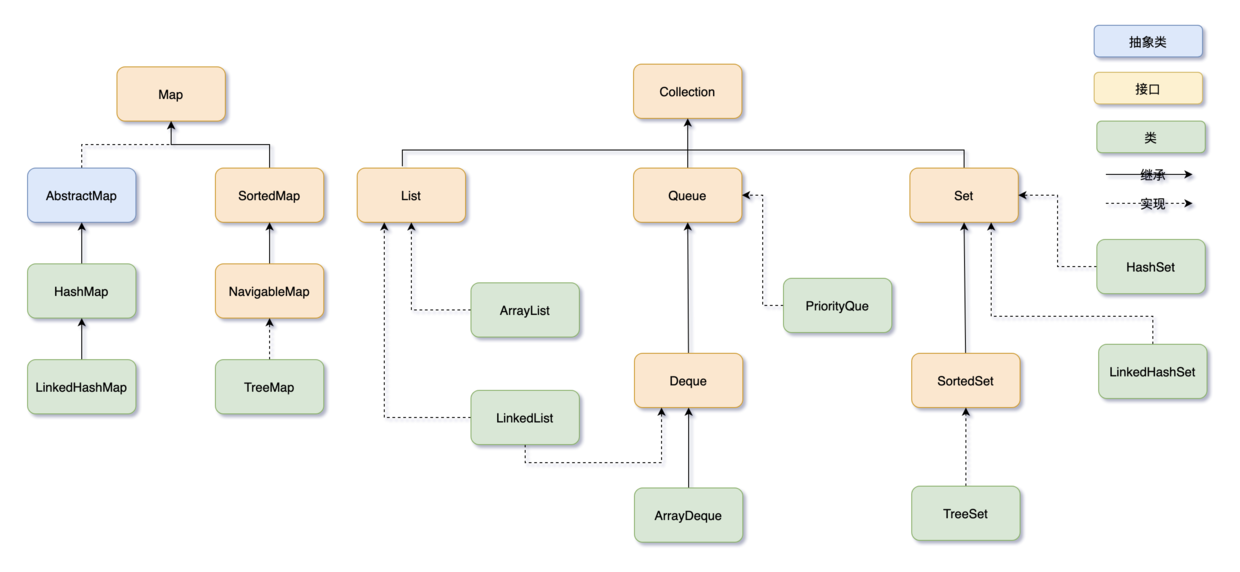
Java集合框架可以分为两条大的支线:
①、Collection,主要由 List、Set、Queue 组成:
- List代表有序、可重复的集合。典型代表就是封装了动态数组的ArrayList和封装了链表的LinkedList;
- Set代表无序、不可重复的集合。典型代表就是HashSet和TreeSet;
- Queue代表队列。典型代表就是双端队列ArrayDeque,以及优先级队列PriorityQueue。
②、Map,代表键值对的集合,典型代表就是HashMap
List
List的特点是存取有序,可以存放重复的元素,可以用下标对元素进行操作
ArrayList
- ArrayList是由数组实现的,支持随机存取,也就是可以通过下标直接存取元素;
- 从尾部插入和删除元素会比较快捷,从中间插入和删除元素会比较低效,因为涉及到数组元素的复制和移动;
- 如果内部数组的容量不足时会自动扩容,因此当元素非常庞大的时候,效率会比较低
LinkedList
- LinkedList是由双向链表实现的,不支持随机存取,只能从一端开始遍历,直到找到需要的元素后返回;
- 任意位置插入和删除元素都很方便,因为只需要改变前一个节点和后一个节点的引用即可,不像ArrayList那样需要复制和移动数组元素;
- 因为每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比ArrayList多一些
Vector和Stack
- Vecotr由动态数组实现,线程安全。被ArrayList取代
- Stack是Vector的一个子类,追加实现先进后出,由动态数组实现,线程安全。被ArrayDeque取代
Set
Set的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作
HashSet
- 由HashMap实现,值由一个固定的Object对象填充,而键用于操作
- 主要用于去重
LinkedHashSet
- 继承自HashSet,由LinkedHashMap实现
- 一种基于哈希表实现的Set接口,它继承自HashSet,并且使用链表维护了元素的插入顺序。因此,它既具有 HashSet的快速查找、插入和删除操作的优点,又可以维护元素的插入顺序
TreeSet
- 由TreeMap实现
- 一种基于红黑树实现的有序集合,它实现了SortedSet接口,可以自动对集合中的元素进行排序。按照键的自然顺序或指定的比较器顺序进行排序
- TreeSet不允许插入null元素,否则会抛出NullPointerException异常
Queue
Queue,队列,通常遵循先进先出(FIFO)的原则,新元素插入到队列尾部,访问元素返回队列头部
ArrayDeque
- 一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点。
- head指向队首的第一个有效的元素,tail指向队尾第一个可以插入元素的空位,因为是循环数组,所以head 不一定从是从0开始,tail 也不一定总是比head大。
LinkedList
- 由双向链表实现。LinkedList一般应该归在List下,只不过也实现了Deque接口,可以作为队列来使用。等于说,LinkedList 同时实现了Stack、Queue、PriorityQueue的所有功能
- 在使用LinkedList作为队列时,可以使用offer()方法将元素添加到队列的末尾,使用poll()方法从队列的头部删除元素。另外,由于 LinkedList 是链表结构,不支持随机访问元素,因此不能使用下标访问元素,需要使用迭代器或者 poll() 方法依次遍历元素。
PriorityQueue
- 一种优先级队列,它的出队顺序与元素的优先级有关,执行remove或者poll方法,返回的总是优先级最高的元素。优先级要求元素实现Comparable接口或者Comparator接口
Map
Map保存的是键值对,键要求保持唯一性,值可以重复
HashMap
- 无序。HashMap实现了Map接口,可以根据键快速地查找对应的值——通过哈希函数将键映射到哈希表中的一个索引位置,从而实现快速访问
- HashMap中的键和值都可以为null。如果键为null,则将该键映射到哈希表的第一个位置。
- 可以使用迭代器或者forEach方法遍历HashMap中的键值对。
- HashMap有一个初始容量和一个负载因子。初始容量是指哈希表的初始大小,负载因子是指哈希表在扩容之前可以存储的键值对数量与哈希表大小的比率。默认的初始容量是16,负载因子是0.75。
LinkedHashMap
- 有序。LinkedHashMap是HashMap的子类,它使用链表来记录插入/访问元素的顺序。LinkedHashMap 可以看作是HashMap+LinkedList的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序
TreeMap
- 实现了SortedMap接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。
- 内部使用红黑树来实现键的排序和查找
==ArrayList详解==
京东实习一面:聊聊Java ArrayList,扩容机制了解吗? | 二哥的Java进阶之路 (javabetter.cn)
add()
private static final int DEFAULT_CAPACITY = 10;
/**
* 将指定元素添加到 ArrayList 的末尾
* @param e 要添加的元素
* @return 添加成功返回 true
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // 确保 ArrayList 能够容纳新的元素
elementData[size++] = e; // 在 ArrayList 的末尾添加指定元素
return true;
}
/**
* 确保 ArrayList 能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void ensureCapacityInternal(int minCapacity) {
// 如果elementData是默认空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 使用 DEFAULT_CAPACITY 和指定容量的最小值中的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity); // 确保容量能够容纳指定容量的元素
}
/**
* 检查并确保集合容量足够,如果需要则增加集合容量。
* @param minCapacity 所需最小容量
*/
private void ensureExplicitCapacity(int minCapacity) {
// 检查是否超出了数组范围,确保不会溢出
if (minCapacity - elementData.length > 0)
// 如果需要增加容量,则调用 grow 方法
grow(minCapacity);
}
/**
* 扩容 ArrayList 的方法,确保能够容纳指定容量的元素
* @param minCapacity 指定容量的最小值
*/
private void grow(int minCapacity) {
// 检查是否会导致溢出,oldCapacity 为当前数组长度
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容至原来的1.5倍
if (newCapacity - minCapacity < 0) // 如果还是小于指定容量的最小值
newCapacity = minCapacity; // 直接扩容至指定容量的最小值
if (newCapacity - MAX_ARRAY_SIZE > 0) // 如果超出了数组的最大长度
newCapacity = hugeCapacity(minCapacity); // 扩容至数组的最大长度
// 将当前数组复制到一个新数组中,长度为 newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}add(int index, E element)
/**
* 在指定位置插入一个元素。
*
* @param index 要插入元素的位置
* @param element 要插入的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public void add(int index, E element) {
rangeCheckForAdd(index); // 检查索引是否越界
ensureCapacityInternal(size + 1); // 确保容量足够,如果需要扩容就扩容
System.arraycopy(elementData, index, elementData, index + 1,
size - index); // 将 index 及其后面的元素向后移动一位
elementData[index] = element; // 将元素插入到指定位置
size++; // 元素个数加一
}set()
/**
* 用指定元素替换指定位置的元素。
* @param index 要替换的元素的索引
* @param element 要存储在指定位置的元素
* @return 先前在指定位置的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public E set(int index, E element) {
rangeCheck(index); // 检查索引是否越界
E oldValue = elementData(index); // 获取原来在指定位置上的元素
elementData[index] = element; // 将新元素替换到指定位置上
return oldValue; // 返回原来在指定位置上的元素
}remove()
/**
* 删除指定位置的元素。
* @param index 要删除的元素的索引
* @return 先前在指定位置的元素
* @throws IndexOutOfBoundsException 如果索引超出范围,则抛出此异常
*/
public E remove(int index) {
rangeCheck(index); // 检查索引是否越界
E oldValue = elementData(index); // 获取要删除的元素
int numMoved = size - index - 1; // 计算需要移动的元素个数
if (numMoved > 0) // 如果需要移动元素,就用 System.arraycopy 方法实现
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // 将数组末尾的元素置为 null,让 GC 回收该元素占用的空间
return oldValue; // 返回被删除的元素
}
/**
* 删除列表中第一次出现的指定元素(如果存在)。
* @param o 要删除的元素
* @return 如果列表包含指定元素,则返回 true;否则返回 false
*/
public boolean remove(Object o) {
if (o == null) { // 如果要删除的元素是 null
for (int index = 0; index < size; index++) // 遍历列表
if (elementData[index] == null) { // 如果找到了 null 元素
fastRemove(index); // 调用 fastRemove 方法快速删除元素
return true; // 返回 true,表示成功删除元素
}
} else { // 如果要删除的元素不是 null
for (int index = 0; index < size; index++) // 遍历列表
if (o.equals(elementData[index])) { // 如果找到了要删除的元素
fastRemove(index); // 调用 fastRemove 方法快速删除元素
return true; // 返回 true,表示成功删除元素
}
}
return false; // 如果找不到要删除的元素,则返回 false
}indexOf()和lastIndexOf()
/**
* 返回指定元素在列表中第一次出现的位置。
* 如果列表不包含该元素,则返回 -1。
* @param o 要查找的元素
* @return 指定元素在列表中第一次出现的位置;如果列表不包含该元素,则返回 -1
*/
public int indexOf(Object o) {
if (o == null) { // 如果要查找的元素是 null
for (int i = 0; i < size; i++) // 遍历列表
if (elementData[i]==null) // 如果找到了 null 元素
return i; // 返回元素的索引
} else { // 如果要查找的元素不是 null
for (int i = 0; i < size; i++) // 遍历列表
if (o.equals(elementData[i])) // 如果找到了要查找的元素
return i; // 返回元素的索引
}
return -1; // 如果找不到要查找的元素,则返回 -1
}
/**
* 返回指定元素在列表中最后一次出现的位置。
* 如果列表不包含该元素,则返回 -1。
* @param o 要查找的元素
* @return 指定元素在列表中最后一次出现的位置;如果列表不包含该元素,则返回 -1
*/
public int lastIndexOf(Object o) {
if (o == null) { // 如果要查找的元素是 null
for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
if (elementData[i]==null) // 如果找到了 null 元素
return i; // 返回元素的索引
} else { // 如果要查找的元素不是 null
for (int i = size-1; i >= 0; i--) // 从后往前遍历列表
if (o.equals(elementData[i])) // 如果找到了要查找的元素
return i; // 返回元素的索引
}
return -1; // 如果找不到要查找的元素,则返回 -1
}contains()
public boolean contains(Object o) {
return indexOf(o) >= 0;
}==LinkedList详解==
LinkedList控诉:我爹都嫌弃我! | 二哥的Java进阶之路 (javabetter.cn)
双向链表,无大小限制
add()
/**
* 将指定的元素添加到列表的尾部。
* @param e 要添加到列表的元素
* @return 始终为 true(根据 Java 集合框架规范)
*/
public boolean add(E e) {
linkLast(e); // 在列表的尾部添加元素
return true; // 添加元素成功,返回 true
}
/**
* 在列表的尾部添加指定的元素。
*
* @param e 要添加到列表的元素
*/
void linkLast(E e) {
final Node<E> l = last; // 获取链表的最后一个节点
final Node<E> newNode = new Node<>(l, e, null); // 创建新的节点设置为链表最后一个节点
last = newNode; // 将新的节点设置为链表的最后一个节点
if (l == null) // 如果链表为空,则将新节点设置为头节点
first = newNode;
else
l.next = newNode; // 否则将新节点链接到链表的尾部
size++; // 增加链表的元素个数
}
addFirst(){...} // 头插法
addLast(){...} // 尾插法 - linkLast()remove()
/**
remove():删除第一个节点 - removeFirst()
remove(int):删除指定位置的节点 - unlink
remove(Object):删除指定元素的节点
removeFirst():删除第一个节点
removeLast():删除最后一个节点
*/
/**
* 删除指定位置上的元素。
* @param index 要删除的元素的索引
* @return 从列表中删除的元素
* @throws IndexOutOfBoundsException 如果索引越界(index < 0 || index >= size())
*/
public E remove(int index) {
checkElementIndex(index); // 检查索引是否越界
return unlink(node(index)); // 删除指定位置的节点,并返回节点的元素
}
/**
* 从链表中删除指定节点。
*
* @param x 要删除的节点
* @return 从链表中删除的节点的元素
*/
E unlink(Node<E> x) {
final E element = x.item; // 获取要删除节点的元素
final Node<E> next = x.next; // 获取要删除节点的下一个节点
final Node<E> prev = x.prev; // 获取要删除节点的上一个节点
if (prev == null) { // 如果要删除节点是第一个节点
first = next; // 将链表的头节点设置为要删除节点的下一个节点
} else {
prev.next = next; // 将要删除节点的上一个节点指向要删除节点的下一个节点
x.prev = null; // 将要删除节点的上一个节点设置为空
}
if (next == null) { // 如果要删除节点是最后一个节点
last = prev; // 将链表的尾节点设置为要删除节点的上一个节点
} else {
next.prev = prev; // 将要删除节点的下一个节点指向要删除节点的上一个节点
x.next = null; // 将要删除节点的下一个节点设置为空
}
x.item = null; // 将要删除节点的元素设置为空
size--; // 减少链表的元素个数
return element; // 返回被删除节点的元素
}set()
/**
* 将链表中指定位置的元素替换为指定元素,并返回原来的元素。
* @param index 要替换元素的位置(从 0 开始)
* @param element 要插入的元素
* @return 替换前的元素
* @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
*/
public E set(int index, E element) {
checkElementIndex(index); // 检查索引是否超出范围
Node<E> x = node(index); // 获取要替换的节点
E oldVal = x.item; // 获取要替换节点的元素
x.item = element; // 将要替换的节点的元素设置为指定元素
return oldVal; // 返回替换前的元素
}
/**
* 获取链表中指定位置的节点。
* @param index 节点的位置(从 0 开始)
* @return 指定位置的节点
* @throws IndexOutOfBoundsException 如果索引超出范围(index < 0 || index >= size())
*/
Node<E> node(int index) {
if (index < (size >> 1)) { // 如果索引在链表的前半部分
Node<E> x = first;
for (int i = 0; i < index; i++) // 从头节点开始向后遍历链表,直到找到指定位置的节点
x = x.next;
return x; // 返回指定位置的节点
} else { // 如果索引在链表的后半部分
Node<E> x = last;
for (int i = size - 1; i > index; i--) // 从尾节点开始向前遍历链表,直到找到指定位置的节点
x = x.prev;
return x; // 返回指定位置的节点
}
}indexOf(Object)和get(int)
/**
* 返回链表中首次出现指定元素的位置,如果不存在该元素则返回 -1。
* @param o 要查找的元素
* @return 首次出现指定元素的位置,如果不存在该元素则返回 -1
*/
public int indexOf(Object o) {
int index = 0; // 初始化索引为 0
if (o == null) { // 如果要查找的元素为 null
for (Node<E> x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
if (x.item == null) // 如果找到了要查找的元素
return index; // 返回该元素的索引
index++; // 索引加 1
}
} else { // 如果要查找的元素不为 null
for (Node<E> x = first; x != null; x = x.next) { // 从头节点开始向后遍历链表
if (o.equals(x.item)) // 如果找到了要查找的元素
return index; // 返回该元素的索引
index++; // 索引加 1
}
}
return -1; // 如果没有找到要查找的元素,则返回 -1
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}==Stack详解==
自定义栈数组实现
class Stack {
private int arr[];
private int top;
private int capacity;
// 初始化栈
Stack(int size) {
arr = new int[size];
capacity = size;
top = -1;
}
// 压栈
public void push(int x) {
if (isFull()) {
System.out.println("溢出\n程序终止\n");
System.exit(1);
}
System.out.println("压入 " + x);
arr[++top] = x;
}
// 出栈
public int pop() {
if (isEmpty()) {
System.out.println("栈是空的");
System.exit(1);
}
return arr[top--];
}
// 返回栈大小
public int size() {
return top + 1;
}
// 判空
public Boolean isEmpty() {
return top == -1;
}
// 判满
public Boolean isFull() {
return top == capacity - 1;
}
}Stack类 (java.util.Stack)继承自Vector,是线程安全
在Java中,推荐使用ArrayDeque来代替Stack,因为ArrayDeque是非线程安全的,性能更好
public class Vector<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
protected Object[] elementData;
protected int elementCount;
protected int capacityIncrement;
}push()
public E push(E item) {
addElement(item);
return item;
}
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}pop()
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}==HashMap详解==
hashmap头插法和尾插法区别_一个跟面试官扯皮半个小时的HashMap(看这一篇就足够了) - 知乎
介绍
HashMap 是 Java 中常用的数据结构之一,用于存储键值对。在 HashMap 中,每个键都映射到一个唯一的值,可以通过键来快速访问对应的值,算法时间复杂度可以达到 O(1)。在实际应用中,HashMap可以用于缓存、索引等场景。
HashMap的实现原理是基于哈希表的,它的底层是一个数组,数组的每个位置可能是一个链表或红黑树,也可能只是一个键值对。当添加一个键值对时,HashMap 会根据键的哈希值计算出该键对应的数组下标(索引),然后将键值对插入到对应的位置。 当通过键查找值时,HashMap会根据键的哈希值计算出数组下标,并查找对应的值
hash方法的原理
hash方法是用来做哈希值优化
hash方法增加了随机性(低位随机性加大,掺杂部分高位特征,高位信息也得到保留),让元素分布更加均衡,减少碰撞
hash 方法的原理是,先获取key对象的 hashCode 值,然后将其高位与低位进行异或操作,得到一个新的哈希值。
为什么要进行异或操作呢?因为对于hashCode的高位和低位,它们的分布是比较均匀的,如果只是简单地将它们加起来或者进行位运算,容易出现哈希冲突,而异或操作可以避免这个问题。
然后将新的哈希值取模(mod),得到一个实际的存储位置。这个取模操作的目的是将哈希值映射到桶(Bucket)的索引上,桶是HashMap中的一个数组,每个桶中会存储着一个链表(或者红黑树),装载哈希值相同的键值对(没有相同哈希值的话就只存储一个键值对)
// hash方法源码 将key的hashCode值进行处理,得到最终的哈希值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
// 如果键值为 null,则哈希码为0(即如果键为null,则存放在第一个位置);
// 否则,通过调用hashCode()方法获取键的哈希码,并将其与右移16位的哈希码进行异或运算
// 将哈希码向右移动16位,相当于将原来的哈希码分成了两个 16 位的部分
// 理论上,哈希值(哈希码)是一个int类型,范围从-2147483648 到 2147483648
// 哈希值是不能直接拿来用的。
// 先和数组长度做与运算((n - 1) & hash)取模预算/取余运算,用得到的值来访问数组下标才行
}HashMap的扩容机制
HashMap扩容是通过resize方法实现。JDK 8中融入了红黑树(链表长度超过8的时候,会将链表转化为红黑树提高查询效率)
当我们往HashMap中不断添加元素时,HashMap会自动进行扩容操作(条件是元素数量达到负载因子(load factor)乘以数组长度时),以保证其存储的元素数量不会超出其容量限制。在进行扩容操作时,HashMap会先将数组的长度扩大一倍,然后将原来的元素重新散列到新的数组中。由于元素的位置是通过key的hash和数组长度进行与运算得到的,因此在数组长度扩大后,元素的位置也会发生一些改变。一部分索引不变,另一部分索引为“原索引+旧容量
JDK 7源码
// newCapacity为新容量
void resize(int newCapacity) {
// 小数组,临时过度下
Entry[] oldTable = table;
// 扩容前旧容量
int oldCapacity = oldTable.length;
// MAXIMUM_CAPACITY 为最大容量,2的30次方 = 1<<30
if (oldCapacity == MAXIMUM_CAPACITY) {
// 容量调整为 Integer 的最大值 0x7fffffff(十六进制)=2的31次方-1
threshold = Integer.MAX_VALUE;
return;
}
// 初始化一个新的数组(大容量)
Entry[] newTable = new Entry[newCapacity];
// 把小数组的元素转移到大数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 引用新的大数组
table = newTable;
// 重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/*
该方法接收一个新的容量 newCapacity,然后将 HashMap 的容量扩大到 newCapacity。
首先,方法获取当前HashMap的旧数组 oldTable 和旧容量oldCapacity。如果旧容量已经达到HashMap支持的最大容量MAXIMUM_CAPACITY(2^30),就将新的阈值threshold 调整为Integer.MAX_VALUE(2^31-1),这是因为HashMap的容量不能超过MAXIMUM_CAPACITY。
因为2^31-1(Integer.MAX_VALUE)-2^30(MAXIMUM_CAPACITY)= 2^30-1,刚好相差一倍
(HashMap 每次扩容都是之前的一倍)
接着,方法创建一个新的数组newTable,将旧数组oldTable中的元素转移到新数组newTable中。转移过程是通过调用transfer方法来实现的。该方法遍历旧数组中的每个桶,并将每个桶中的键值对重新计算哈希值后,将其插入到新数组对应的桶中。
转移完成后,方法将HashMap内部的数组引用table指向新数组newTable,并重新计算阈值 threshold。新的阈值是新容量newCapacity乘以负载因子loadFactor的结果,但如果计算结果超过了HashMap支持的最大容量 MAXIMUM_CAPACITY,则将阈值设置为MAXIMUM_CAPACITY + 1,这是因为HashMap的元素数量不能超过 MAXIMUM_CAPACITY。
*/
// 新容量newCapacity的计算,可以避免新容量太小或太大导致哈希冲突过多或者浪费空间
int newCapacity = oldCapacity * 2;
if (newCapacity < 0 || newCapacity >= MAXIMUM_CAPACITY) {
newCapacity = MAXIMUM_CAPACITY;
} else if (newCapacity < DEFAULT_INITIAL_CAPACITY) {
newCapacity = DEFAULT_INITIAL_CAPACITY;
}
// transfer 方法用来转移,将旧的小数组元素拷贝到新的大数组中
void transfer(Entry[] newTable, boolean rehash) {
// 新的容量
int newCapacity = newTable.length;
// 遍历小数组
for (Entry<K,V> e : table) {
while(null != e) {
// 拉链法,相同 key 上的不同值
Entry<K,V> next = e.next;
// 是否需要重新计算 hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 根据大数组的容量,和键的 hash 计算元素在数组中的下标
int i = indexFor(e.hash, newCapacity);
// 同一位置上的新元素被放在链表的头部
e.next = newTable[i];
// 放在新的数组上
newTable[i] = e;
// 链表上的下一个元素
e = next;
}
}
}
/*
该方法接受一个新的 Entry 数组 newTable 和一个布尔值 rehash 作为参数,其中 newTable 表示新的哈希表,rehash 表示是否需要重新计算键的哈希值。
在方法中,首先获取新哈希表(数组)的长度newCapacity,然后遍历旧哈希表中的每个Entry。对于每个Entry,使用拉链法将相同key值的不同value值存储在同一个链表中。如果rehash为true,则需要重新计算键的哈希值,并将新的哈希值存储在Entry的hash属性中。
接着,根据新哈希表的长度和键的哈希值,计算Entry在新数组中的位置i,然后将该Entry添加到新数组的 i 位置上。由于新元素需要被放在链表的头部,因此将新元素的下一个元素设置为当前数组位置上的元素。
最后,遍历完旧哈希表中的所有元素后,转移工作完成,新的哈希表 newTable 已经包含了旧哈希表中的所有元素
*/拉链法使用了单链表的头插入方式,会导致在旧数组中同一个链表上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上
JDK 8源码
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table; // 获取原来的数组 table
int oldCap = (oldTab == null) ? 0 : oldTab.length; // 获取数组长度 oldCap
int oldThr = threshold; // 获取阈值 oldThr
int newCap, newThr = 0;
if (oldCap > 0) { // 如果原来的数组 table 不为空
if (oldCap >= MAXIMUM_CAPACITY) { // 超过最大值就不再扩充了,就只好随你碰撞去吧
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的 resize 上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // 将新阈值赋值给成员变量 threshold
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建新数组 newTab
table = newTab; // 将新数组newTab赋值给成员变量 table
if (oldTab != null) { // 如果旧数组oldTab不为空
for (int j = 0; j < oldCap; ++j) { // 遍历旧数组的每个元素
Node<K,V> e;
if ((e = oldTab[j]) != null) { // 如果该元素不为空
oldTab[j] = null; // 将旧数组中该位置的元素置为null,以便垃圾回收
if (e.next == null) // 如果该元素没有冲突
newTab[e.hash & (newCap - 1)] = e; // 直接将该元素放入新数组
else if (e instanceof TreeNode) // 如果该元素是树节点
// 将该树节点分裂成两个链表
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 如果该元素是链表
Node<K,V> loHead = null, loTail = null; // 低位链表的头结点和尾结点
Node<K,V> hiHead = null, hiTail = null; // 高位链表的头结点和尾结点
Node<K,V> next;
do { // 遍历该链表
next = e.next;
if ((e.hash & oldCap) == 0) { // 如果该元素在低位链表中
if (loTail == null) // 低位链表没有结点
loHead = e; // 将该元素作为低位链表的头结点
else // 低位链表已有结点
loTail.next = e; // 将该元素加入低位链尾部
loTail = e; // 更新低位链表的尾结点
}
else { // 如果该元素在高位链表中
if (hiTail == null) // 如果高位链表还没有结点
hiHead = e; // 将该元素作为高位链表头结点
else // 如果高位链表已经有结点
hiTail.next = e; // 将该元素加入高位链表的尾部
hiTail = e; // 更新高位链表的尾结点
}
} while ((e = next) != null); //
if (loTail != null) { // 如果低位链表不为空
loTail.next = null; // 将低位链表的尾结点指向 null,以便垃圾回收
newTab[j] = loHead; // 将低位链表作为新数组对应位置的元素
}
if (hiTail != null) { // 如果高位链表不为空
hiTail.next = null; // 将高位链表的尾结点指向 null,以便垃圾回收
newTab[j + oldCap] = hiHead; // 将高位链表作为新数组对应位置的元素
}
}
}
}
}
return newTab; // 返回新数组
}
/*
1、获取原来的数组table、数组长度 oldCap 和阈值 oldThr。
2、如果原来的数组table 不为空,则根据扩容规则计算新数组长度newCap和新阈值newThr,然后将原数组中的元素复制到新数组中。
3、如果原来的数组table为空但阈值oldThr不为零,则说明是通过带参数构造方法创建的HashMap,此时将阈值作为新数组长度newCap。
4、如果原来的数组table和阈值oldThr都为零,则说明是通过无参数构造方法创建的HashMap,此时将默认初始容量DEFAULT_INITIAL_CAPACITY(16)和默认负载因子DEFAULT_LOAD_FACTOR(0.75)计算出新数组长度newCap和新阈值newThr。
5、计算新阈值threshold,并将其赋值给成员变量threshold。
6、创建新数组newTab,并将其赋值给成员变量table。
7、如果旧数组oldTab不为空,则遍历旧数组的每个元素,将其复制到新数组中。
8、返回新数组newTab
*/JDK7 索引的计算方式hashCode % table.length
JDK8 索引的计算方式hash & (newCapacity - 1)
在JDK 8的新hash算法下,数组扩容后的索引位置,要么就是原来的索引位置,要么就是“原索引+原来的容量”,遵循一定规律
加载因子为什么是0.75
加载因子是用来表示HashMap中数据的填满程度.加载因子=填入哈希表中的数据个数/哈希表的长度
HashMap 是通过拉链法来解决哈希冲突的。为了减少哈希冲突发生概率,当HashMap的数组长度达到一个临界值的时候,就会触发扩容,扩容后会将之前小数组中的元素转移到大数组中,这是一个相当耗时的操作。临界值=初始容量*加载因子
Java 8之前,HashMap使用链表来解决冲突,即当两个或者多个键映射到同一个桶时,它们被放在同一个桶的链表上。当链表上的节点(Node)过多时,链表会变得很长,查找的效率(LinkedList的查找效率为 O(n))就会受到影响。
Java 8中,当链表的节点数超过一个阈值(8)时,链表将转为红黑树(节点为TreeNode),红黑树(TreeMap)是一种高效的平衡树结构,能够在 O(log n)的时间内完成插入、删除和查找等操作。这种结构在节点数很多时,可以提高HashMap的性能和可伸缩性
理想情况下,在随机hashCode下,节点在桶中的频率遵循泊松分布,平均缩放阈值为0.75,忽略方差,列表大小k的预期出现次数为(exp(-0.5)* pow(0.5,k)/ factorial(k))
一般选择0.75,是因为这个值可以在时间和空间成本之间做到一个折中,使得哈希表的性能达到较好的表现。
如果负载因子过大,填充因子较多,那么哈希表中的元素就会越来越多地聚集在少数的桶中,这就导致了冲突的增加,这些冲突会导致查找、插入和删除操作的效率下降。同时,这也会导致需要更频繁地进行扩容,进一步降低了性能。
如果负载因子过小,那么桶的数量会很多,虽然可以减少冲突,但是在空间利用上面也会有浪费,因此选择0.75是为了取得一个平衡点,即在时间和空间成本之间取得一个比较好的平衡点
线程不安全
三方面原因
- 多线程下扩容会死循环
- JDK 7时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面。扩容的时候就有可能导致出现环形链表,造成死循环
- JDK 8时已经修复了这个问题,扩容时会保持链表原来的顺序
- 多线程下put会导致元素丢失
- 计算index,并对null做处理。多个线程同时插入空桶,导致后者覆盖前者,先插入元素丢失
- put和get并发时会导致get到null
- 线程1执行put时,因为元素个数超出阈值而导致出现扩容,线程2此时执行get,就有可能出现这个问题
HashMap是线程不安全的主要是因为它在进行插入、删除和扩容等操作时可能会导致链表的结构发生变化,从而破坏了 HashMap的不变性。具体来说,如果在一个线程正在遍历HashMap的链表时,另外一个线程对该链表进行了修改(比如添加了一个节点),那么就会导致链表的结构发生变化,从而破坏了当前线程正在进行的遍历操作,可能导致遍历失败或者出现死循环等问题。
为了解决这个问题,Java提供线程安全的HashMap实现类ConcurrentHashMap。ConcurrentHashMap内部采用分段锁(Segment),将整个Map拆分为多个小的HashMap,每个小HashMap都有自己的锁,不同线程可以同时访问不同小 Map,从而实现线程安全。在进行插入、删除和扩容等操作时,只需锁住当前小Map,不会对整个Map 进行锁定,提高了并发访问效率。
小结
- HashMap采用数组+链表/红黑树的存储结构,能够在O(1)的时间复杂度内实现元素的添加、删除、查找等操作。
- HashMap是线程不安全的,因此在多线程环境下需要使用ConcurrentHashMap来保证线程安全。
- HashMap的扩容机制是通过扩大数组容量和重新计算hash值来实现的,扩容时需要重新计算所有元素的hash值,因此在元素较多时扩容会影响性能。
- 在Java 8中,HashMap的实现引入了拉链法、树化等机制来优化大量元素存储的情况,进一步提升了性能。
- HashMap中key是唯一的,如果要存储重复的 key,则后面的值会覆盖前面的值。
- HashMap 的初始容量和加载因子都可以设置,初始容量表示数组的初始大小,加载因子表示数组的填充因子。一般情况下,初始容量为16,加载因子为0.75。
- HashMap在遍历时是无序的,因此如果需要有序遍历,可以使用TreeMap。
==LinkedHashMap详解==
LinkedHashMap可以维持插入顺序
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// put调用的内部方法newNode()
HashMap.Node<K,V> newNode(int hash, K key, V value, HashMap.Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<>(hash, key, value, e);
linkNodeLast(p);
return p;
}
/**
* 将指定节点插入到链表的尾部
* @param p 要插入的节点
*/
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail; // 获取链表的尾节点
tail = p; // 将p设为尾节点
if (last == null)
head = p; // 如果链表为空,则将p设为头节点
else {
p.before = last; // 将p的前驱节点设为链表的尾节点
last.after = p; // 将链表的尾节点的后继节点设为p
}
}
}
// LinkedHashMap<String, String> map = new LinkedHashMap<>(16, .75f, true);
// 第三个参数为true表示LinkedHashMap要维护访问顺序;否则不维护插入顺序。默认是false最不经常访问的放在头部。可以使用LinkedHashMap来实现LRU缓存
void afterNodeAccess(Node<K,V> p) { } // 在调用 get() 方法的时候被调用
void afterNodeInsertion(boolean evict) { } // 在调用 put() 方法的时候被调用
void afterNodeRemoval(Node<K,V> p) { } // 在调用 remove() 方法的时候被调用小结
LinkedHashMap 继承自 HashMap,它在 HashMap 的基础上,增加了一个双向链表来维护键值对的顺序。这个链表可以按照插入顺序或访问顺序排序,它的头节点表示最早插入或访问的元素,尾节点表示最晚插入或访问的元素。这个链表的作用就是让 LinkedHashMap 可以保持键值对的顺序,并且可以按照顺序遍历键值对。
LinkedHashMap 还提供了两个构造方法来指定排序方式,分别是按照插入顺序排序和按照访问顺序排序。在按照访问顺序排序的情况下,每次访问一个键值对,都会将该键值对移到链表的尾部,以保证最近访问的元素在最后面。如果需要删除最早加入的元素,可以通过重写 removeEldestEntry() 方法来实现。
==TreeMap详解==
TreeMap由红黑树实现,可以保持元素的自然顺序,或者实现了Comparator接口的自定义顺序
红黑树
节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持二叉树的平衡。
- 1)每个节点都只能是红色或者黑色
- 2)根节点是黑色
- 3)每个叶节点(NIL 节点,空节点)是黑色的。
- 4)如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
- 5)从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
由于红黑树的平衡度比AVL树稍低,因此在进行插入和删除操作时需要进行的旋转操作较少,但是查找效率仍然较高。红黑树适用于读写操作比较均衡的场景。
自然顺序
默认情况下TreeMap根据key的自然顺序排列
自定义排序
可以在声明TreeMap对象的时候指定排序规则
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}排序
lastKey(); // 获取最后一个key
firstKey(); // 获取第一个key
headMap(); // 获取到指定key之前的 key
tailMap(); // 获取指定key之后的key(包括指定key)
subMap(); // [a,b)区间的keyMap
| 特性 | TreeMap | HashMap | LinkedHashMap |
|---|---|---|---|
| 排序 | 支持 | 不 | 不 |
| 插入顺序 | 不 | 不 | 保证 |
| 查找效率 | O(log n) | O(1) | O(1) |
| 空间占用 | 通常较大 | 通常较小 | 通常较大 |
| 适用场景 | 需要排序的场景 | 无需排序的场景 | 需要保持插入顺序 |
==ArrayDeque详解==
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{}当需要使用栈时,Java已不推荐使用Stack,而是推荐使用更高效的ArrayDeque(双端队列)
需要使用队列的时候,也可以选择ArrayDeque
栈和队列
Deque接口。Deque的含义是“double ended queue”,即双端队列,它既可以当作栈使用,也可以当作队列使用。
Deque与Queue对应接口
Queue Method Equivalent Deque Method 说明 add(e) addLast(e) 向队尾插入元素,失败则抛出异常 offer(e) offerLast(e) 向队尾插入元素,失败则返回 falseremove() removeFirst() 获取并删除队首元素,失败则抛出异常 poll() pollFirst() 获取并删除队首元素,失败则返回 nullelement() getFirst() 获取但不删除队首元素,失败则抛出异常 peek() peekFirst() 获取但不删除队首元素,失败则返回 nullDeque与Stack对应接口
Stack Method Equivalent Deque Method 说明 push(e) addFirst(e) 向栈顶插入元素,失败则抛出异常 无 offerFirst(e) 向栈顶插入元素,失败则返回 falsepop() removeFirst() 获取并删除栈顶元素,失败则抛出异常 无 pollFirst() 获取并删除栈顶元素,失败则返回 nullpeek() getFirst() 获取但不删除栈顶元素,失败则抛出异常 无 peekFirst() 获取但不删除栈顶元素,失败则返回 null
ArrayDeque
ArrayDeque底层通过数组实现,为了满足可以同时在数组两端插入或删除元素的需求,该数组必须是循环的,即循环数组(circular array),也就是说数组的任何一点都可能被看作起点或者终点
ArrayDeque非线程安全(not thread-safe),当多个线程同时使用时需要手动同步;另外,该容器不允许放入null元素
head指向首端第一个有效元素,tail指向尾端第一个可以插入元素的空位
插入
public void addFirst(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;//2.下标是否越界
if (head == tail)//1.空间是否够用
doubleCapacity();//扩容
}
// 空间问题是在插入之后解决的,因为tail总是指向下一个可插入的空位,
// 意味着elements数组至少有一个空位,所以插入元素的时候不用考虑空间问题
// 下标越界处理 head = (head - 1) & (elements.length - 1),相当于取余,同时解决head为负值情况
// doubleCapacity() 申请一个更大的数组(原数组的两倍)复制数组(head右侧 + head左侧)
public void addLast(E e) {
if (e == null)//不允许放入null
throw new NullPointerException();
elements[tail] = e;//赋值
if ( (tail = (tail + 1) & (elements.length - 1)) == head)//下标越界处理
doubleCapacity();//扩容
}删除并返回
public E pollFirst() {
E result = elements[head];
if (result == null)//null值意味着deque为空
return null;
elements[h] = null;//let GC work
head = (head + 1) & (elements.length - 1);//下标越界处理
return result;
}
public E pollLast() {
int t = (tail - 1) & (elements.length - 1);//tail的上一个位置是最后一个元素
E result = elements[t];
if (result == null)//null值意味着deque为空
return null;
elements[t] = null;//let GC work
tail = t;
return result;
}返回
public E peekFirst() {
return elements[head]; // elements[head] is null if deque empty
}
public E peekLast() {
return elements[(tail - 1) & (elements.length - 1)];
}小结
ArrayDeque是Java标准库中的一种双端队列实现,底层基于数组实现。与LinkedList相比,ArrayDeque性能更优,因为它使用连续的内存空间存储元素,可以更好地利用CPU缓存,在大多数情况下也更快。
使用LinkedList时,需要频繁进行内存分配和释放,而ArrayDeque在创建时就一次性分配了连续的内存空间,不需要频繁进行内存分配和释放,这样可以更好地利用CPU缓存,提高访问效率。
rrayDeque的扩容策略(当ArrayDeque中的元素数量达到数组容量时,就需要进行扩容操作,扩容时会将数组容量扩大为原来的两倍)可以在一定程度上减少数组复制的次数和时间消耗,同时保证ArrayDeque的性能和空间利用率。
==PriorityQueue详解==
PriorityQueue是Java中的一个基于优先级堆的优先队列实现,它能够在O(log n)时间复杂度内实现元素的插入和删除操作,并且能够自动维护队列中元素的优先级顺序
堆是一种完全二叉树,堆的特点是根节点的值最小(小顶堆)或最大(大顶堆),并且任意非根节点i的值都不大于(或不小于)其父节点的值。因为完全二叉树的结构比较规则,所以可以使用数组来存储堆的元素,而不需要使用指针等额外的空间。在堆中,每个节点的下标和其在数组中的下标是一一对应的,假设节点下标为i,则其父节点下标为i/2,其左子节点下标为2i,其右子节点下标为2i+1
siftUp()
// 用于插入元素x并维持堆的特性
// 调整的过程为:
// 从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}siftDown()
// 对堆进行调整
// 从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x<=左右孩子中的任何一个为止
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}小结
PriorityQueue 是一个非常常用的数据结构,它是一种特殊的堆(Heap)实现,可以用来高效地维护一个有序的集合。
- 它的底层实现是一个数组,通过堆的性质来维护元素的顺序。
- 取出元素时按照优先级顺序(从小到大或者从大到小)进行取出。
- 如果需要指定排序,元素必须实现 Comparable 接口或者传入一个 Comparator 来进行比较
==ArrayList和LinkedList的区别==

==深入理解Java泛型==
Java基础( 泛型之 和 上下界限) - 个人文章 - SegmentFault 思否
使用类型参数解决了元素的不确定性
一个泛型类就是具有一个或多个类型变量的类。可以在一个非泛型的类(或者泛型类)中定义泛型方法
限定符 extends 可以缩小泛型的类型范围
Java虚拟机会将泛型的类型变量擦除,并替换为限定类型(没有限定的话,就用Object)
通配符使用英文的问号(?)来表示。在我们创建一个泛型对象时,可以使用关键字 extends 限定子类,也可以使用关键字 super限定父类
小结
在Java中,泛型是一种强类型约束机制,可以在编译期间检查类型安全性,并且可以提高代码的复用性和可读性
- 类型参数化
- 泛型的本质是参数化类型,也就是说,在定义类、接口或方法时,可以使用一个或多个类型参数来表示参数化类型
- 类型擦除
- 泛型在编译时会将泛型类型擦除,将泛型类型替换成Object类型。这是为了向后兼容,避免对原有Java代码造成影响
- Java泛型只在编译时起作用,运行时并不会保留泛型类型信息
- 通配符
- 通配符用于表示某种未知的类型。使用通配符可以使方法更加通用,同时保证类型安全。
- 上限通配符
<? extends T>,表示通配符只能接受T或T的子类 - 下限通配符(Lower Bounded Wildcards)用super关键字来声明,其语法形式为
<? super T>,其中 T 表示类型参数。它表示的是该类型参数必须是某个指定类的超类(包括该类本身)
==Iterator和Iterable区别==
// 在Java中,我们对List进行遍历的时候,主要有这么三种方式
// 1. for循环
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
// 2. 迭代器
Iterator it = list.iterator();
while(it.hasNext()) {
it.next();
}
// 3. for-each 本质是Iterator
for (Object ob : list) {
ob;
}Iterator是个接口,JDK1.2的时候就有了,用来改进Enumeration接口:
- 允许删除元素(增加了remove方法)
- 优化了方法名(Enumeration中是hasMoreElements和nextElement,不简洁)
Iterator源码
public interface Iterator<E> {
// 判断集合中是否存在下一个对象
boolean hasNext();
// 返回集合中的下一个对象,并将访问指针移动一位
E next();
// 删除集合中调用next()方法返回的对象
default void remove() {
throw new UnsupportedOperationException("remove");
}
// JDK1.8时,Iterable接口中新增forEach方法
/*
该方法实现时首先会对 action 参数进行非空检查,为null抛出NullPointerException异常。
然后使用for-each循环遍历集合中的元素,并对每个元素调用action.accept(t)方法执行指定的操作。
由于Iterable是Java集合框架中所有集合类型的基本接口,该方法可被所有实现Iterable接口集合类型使用
*/
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}Iterable接口
public interface Iterable<T> {
Iterator<T> iterator();
}==Java foreach循环陷阱==
为什么阿里的Java开发手册里会强制不要在foreach里进行元素的删除操作?
fail-fast
- 一种通用的系统设计思想,一旦检测到可能会发生错误,就立马抛出异常,程序将不再往下执行
protected transient int modCount = 0;foreach循环反编译后,生成迭代器遍历但调用的是集合自身的remove(E)方法。
- remove方法调用fastRemove方法
- fastRemove方法中会执行
modCount++
下次遍历后,执行迭代器的next方法。next方法调用checkForComodification方法。检查修改次数是否一致
在迭代ArrayList时,如果迭代过程中发现modCount的值与迭代器的expectedModCount不一致,则说明ArrayList已被修改过,此时会抛出ConcurrentModificationException异常。这种机制可以保证迭代器在遍历ArrayList时,不会遗漏或重复元素,同时也可以在多线程环境下检测到并发修改问题。
小结
因为foreach循环是基于迭代器实现的,而迭代器在遍历集合时会维护一个expectedModCount属性来记录集合被修改的次数。如果在foreach循环中执行删除操作会导致expectedModCoun 属性值与实际的modCount属性值不一致,从而导致迭代器的hasNext()和next()方法抛出ConcurrentModificationException异常。
为了避免这种情况,应该使用迭代器的remove()方法来删除元素,该方法会在删除元素后更新迭代器状态,确保循环的正确性。如果需要在循环中删除元素,应该使用迭代器的remove()方法,而不是集合自身的remove()方法。
正确删除元素
- remove后break
- break后循环就不再遍历了,意味着Iterator的next方法不再执行了,也就意味着
checkForComodification方法不再执行了,所以异常也就不会抛出 - 当 List 中有重复元素要删除的时候,break不合适
- break后循环就不再遍历了,意味着Iterator的next方法不再执行了,也就意味着
- for循环
- 可以避开fail-fast保护机制,也就说remove元素后不再抛出异常
- 程序在原则上是有问题的。list的大小在remove 后发生了变化,有元素被跳过
- 使用Iterator
- Iterator的remove方法就可以避开fail-fast保护机制
- 删除完会执行
expectedModCount = modCount,保证了expectedModCount与modCount的同步
==Comparable和Comparator区别==
Comparable
public interface Comparable<T> {
int compareTo(T t);
}
// compareTo() 方法
// 该方法的返回值可能为负数,零或者正数,
// 代表该对象按排序规则小于、等于或者大于要比较的对象。
// 如果指定对象的类型与此对象不能进行比较,则引发ClassCastException异常。指定泛型可以有效避免如果一个类实现了Comparable接口(只需要重写compareTo()`方法),就可以按照自制定规则将由它创建的对象进行比较
Comparator
Comparator接口的定义更复杂,核心方法有两个compare()和equals()
可以让类E保持原貌,不主动实现Comparable接口。而是新建类实现Comparator<E>接口,可以实现多个比较器类
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
}
// compare(T o1, T o2) 返回值可能为负数,零或者正数,代表第一个对象小于、等于或者大于第二个对象。
// equals(Object obj) 需要传入一个Object作为参数,并判断该 Object是否和Comparator保持一致Comparable和Comparator的区别
- 一个类实现Comparable接口,意味着该类对象可以直接进行比较(排序),但比较(排序)方式只有一种,单一。
- 一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现Comparator接口)。
- Comparable接口在
java.lang包下,而Comparator接口在java.util包下 - 对象排序需要基于自然顺序选择
Comparable,需要按照对象不同属性进行排序选择Comparator
==详解WeakHashMap==
WeakHashMap其实和HashMap大多数行为是一样的,只是WeakHashMap不会阻止GC回收key对象(不是value)
WeakHashMap如何不阻止对象回收
- WeakHashMap的Entry继承了WeakReference。
- 其中Key作为了WeakReference指向的对象
- 因此WeakHashMap利用了WeakReference的机制来实现不阻止GC回收Key
private static final class Entry<K, V>
extends WeakReference<K> implements Map.Entry<K, V> {
int hash;
boolean isNull;
V value;
Entry<K, V> next;
interface Type<R, K, V> {
R get(Map.Entry<K, V> entry);
}
Entry(K key, V object, ReferenceQueue<K> queue) {
super(key, queue);
isNull = key == null;
hash = isNull ? 0 : key.hashCode();
value = object;
}
}如何删除被回收的key数据
在Javadoc中关于WeakHashMap有这样的描述,当key不再引用时,其对应的key/value也会被移除。
那么是如何移除的呢,这里我们通常有两种假设策略
- 当对象被回收的时候进行通知
- Java中没有一个可靠的通知回调,比如大家常说的finalize方法,其实也不是标准的,不同的JVM可以实现不同,甚至是不调用这个方法。故没有使用通知策略
- WeakHashMap轮询处理失效的Entry
- WeakHashMap采用轮询形式,在put/get/size等方法调用时都会先调用一个poll方法,检查并删除失效Entry
Java IO
==IO知识体系==

IO,即in-out,输入-输出,指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接
Java中是通过流处理IO
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道
- 先进先出
- 顺序存储 (RandomAccessFile可随机访问)
- 只读或只写(每个流只能是输入流或输出流的一种,不能同时具备两个功能)
传输方式划分 - 4个抽象类
- 字节(byte) 通常情况下,一个字节有 8 位(bit)。
- InputStream类
int read()读取数据int read(byte b[], int off, int len):从第off位置开始读,读取len长度的字节,放入数组blong skip(long n)跳过指定个数的字节int available()返回可读的字节数void close()关闭流,释放资源
- OutputStream类
void write(int b)写入一个字节,虽然参数是一个int类型,但只有低8位会写入,高24位舍弃void write(byte b[], int off, int len)将数组b从off位置开始,长度为len的字节写入void flush()强制刷新,将缓冲区的数据写入void close()关闭流
- InputStream类
- 字符(char) 可以是计算机中使用的字母数字符号。
- Reader类
int read()读取单个字符int read(char cbuf[], int off, int len)从第off位置开始读,读取len长度字符,放入数组blong skip(long n)跳过指定个数的字符int ready()是否可以读了void close()关闭流,释放资源
- Writer类
void write(int c)写入一个字符void write(char cbuf[], int off, int len)将数组cbuf从off位置开始,长度为len的字符写入void flush()强制刷新,将缓冲区的数据写入void close()关闭流
- Reader类
- 字节流可以处理一切文件,而字符流只能处理文本
字节流和字符流的区别
字节流一般用来处理图像、视频、音频、PPT、Word等类型的文件。
字符流一般用于处理纯文本类型的文件,不能处理图像视频等非文本文件。
字节流可以处理一切文件,而字符流只能处理纯文本文件。
字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升大。
字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升小。
操作对象划分 - 文件、数组(内存)、管道、基本数据类型、缓冲、打印、对象序列化/反序列化、转换
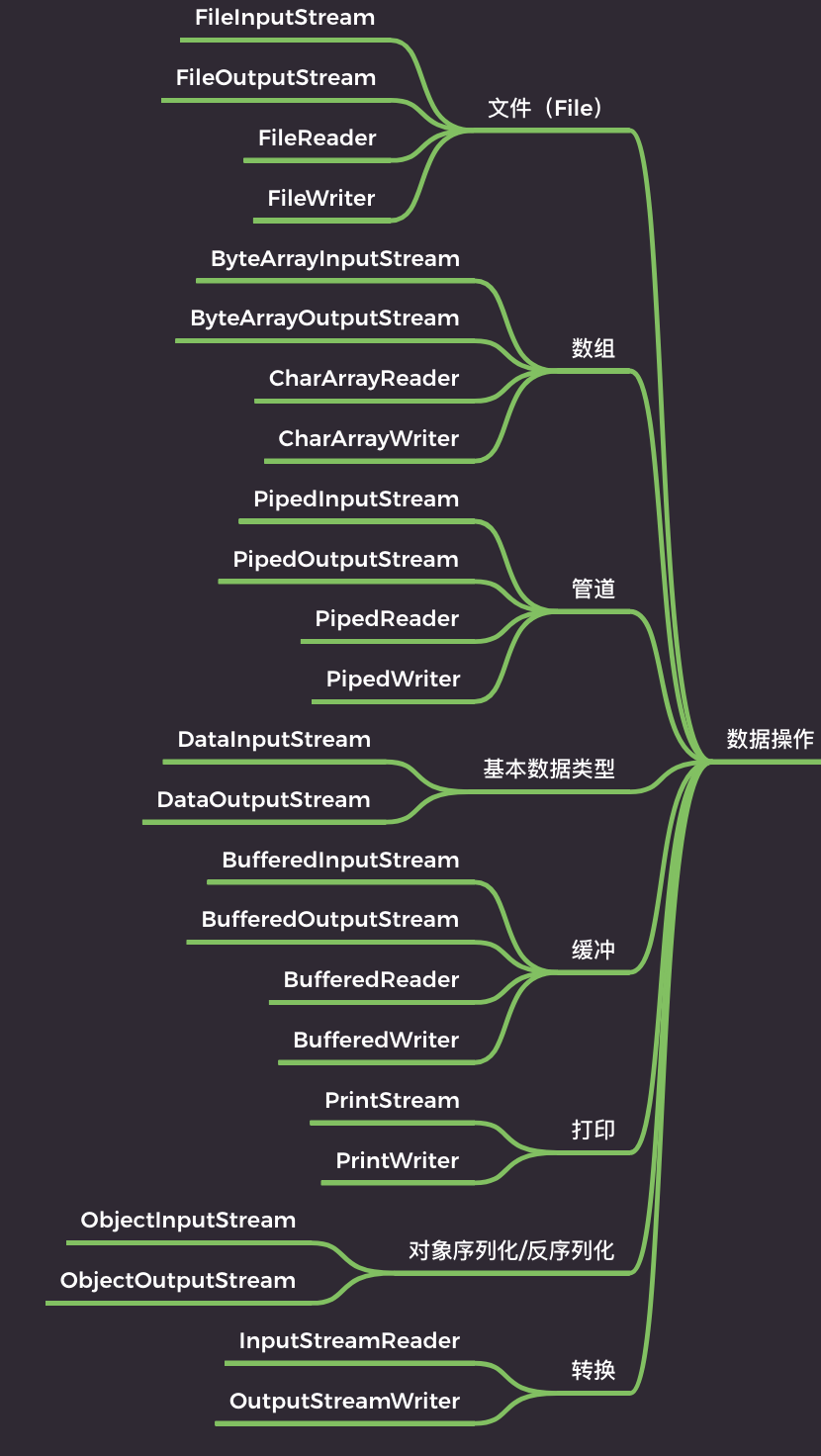
- 文件
- 直接操作文件的流
- 字节流(FileInputStream和FileOuputStream)和字符流(FileReader和FileWriter)
- 数组(内存)
- 文件读写操作可以使用文件流配合缓冲流
- 为了提升频繁读写文件时的效率,可用数组流/内存流
- 数组流可以用于在内存中读写数据。
- 优点是不需要创建临时文件,可以提高程序的效率。
- 缺点是只能存储有限数据量,存储数据量过大会导致内存溢出
- 管道
- Java中,通信双方必须在同一个进程中,也就是在同一个JVM中,管道为线程之间的通信提供了通信能力
- 基本数据类型
- 字节流读写基本数据类型DataInputStream和DataOutputStream
- 缓冲
- 为了减少程序和硬盘的交互,提升程序的效率,引入缓冲流(类名前缀带有Buffer)
- 打印
- 用于打印输出数据的类,包括 PrintStream和PrintWriter
- 对象序列化/反序列化
- 序列化本质上是将一个Java对象转成字节数组,然后可以将其保存到文件中,或者通过网络传输到远程
- ObjectInputStream和ObjectOutputStream
- 转换
- InputStreamReader 字节流 -> 字符流. 使用指定的字符集读取字节并将它们解码为字符
- OutputStreamWriter 字符流 -> 字节流. 将字符流输出对象变为字节流输出对象
- 使用转换流可以方便地在字节流和字符流之间进行转换。
- 在进行文本文件读写时,通常使用字符流进行操作
- 在进行网络传输或与设备进行通信时,通常使用字节流进行操作
==文件流==
File
java.io.File 类专门对文件进行操作.只能对文件本身进行操作,不能对文件内容进行操作。操作内容必须借助输入输出流
File类是文件和目录的抽象表示,主要用于文件和目录的创建、查找和删除等操作
File构造方法
File(String pathname)通过给定的路径来创建新的File实例File(String parent, String child)从父路径(字符串)和子路径创建新的File实例File(File parent, String child)从父路径(File)和子路径名字符串创建新的File实例
File 类构造方法不会检验文件或目录是否真实存在,因此无论该路径下是否存在文件或者目录,都不影响File对象的创建
macOS路径使用正斜杠(/)作为路径分隔符,Windows路径使用反斜杠(\)作为路径分隔符。
Java 中提供了一个跨平台的方法来获取路径分隔符File.separator,会根据操作系统自动返回正确的路径分隔符
File常用方法
- 获取
getAbsolutePath()/getPath()绝对路径getName()文件名或目录名。length()文件长度,以字节为单位
- 判断
exists():判断文件或目录是否存在isDirectory():判断是否为目录isFile():判断是否为文件
- 创建 / 删除
createNewFile()文件不存在,创建一个空文件并返回true,文件存在,不创建文件并返回false。delete()删除文件或目录。如果是目录,只有目录为空才能删除。mkdir()只能创建一级目录。父目录不存在会创建失败。返回true/falsemkdirs()可以创建多级目录。父目录不存在会一并创建。返回true/false
- 遍历
String[] list()返回一个String数组,表示该File目录中的所有子文件或目录File[] listFiles()返回一个File数组,表示该File目录中的所有子文件或目录
RandomAccessFile
既可读文件,也可写文件
允许在文件中随机访问数据,如数据库系统
构造方法
RandomAccessFile(File file / String name, String mode)使用给定文件对象或文件名和访问模式创建
访问模式
"r"只读模式。调用结果对象的任何 write 方法都将导致IOException。"rw"读写模式。如果文件不存在将被创建。"rws"读写模式,并要求对内容或元数据的每个更新都被立即写入到底层存储设备。 这种模式是同步的,可以确保在系统崩溃时不会丢失数据。
"rwd"读写模式,仅要求对文件内容的更新被立即写入。元数据可能会被延迟写入
void seek(long pos)将文件指针设置到文件中的pos位置
Apache FileUtils类
Apache Commons IO库中的一个类,提供了更为方便的方法来操作文件或目录
// 复制
FileUtils.copyFile(srcFile, destFile); // 文件
FileUtils.copyDirectory(srcFile, destFile); // 目录
// 删除
FileUtils.delete(file);
// 移动
FileUtils.moveFile(srcFile, destFile);
// 查询信息
Date modifyTime = FileUtils.lastModified(file);
long size = FileUtils.sizeOf(file);
String extension = FileUtils.getExtension(file.getName());Hutool FileUtil类
// 复制
FileUtil.copyFile(file, dest);
// 移动
FileUtil.move(file, dest, true);
// 删除
FileUtil.del(file);
// 重命名
FileUtil.rename(file, "FileUtilDemo3.java", true);
// readLines
FileUtil.readLines(file, "UTF-8").forEach(System.out::println);==字节流==
字节输出流(OutputStream)
java.io.OutputStream是字节输出流的超类(父类),它定义的一些共性方法:
close():关闭此输出流并释放与此流相关联的系统资源flush():刷新此输出流并强制缓冲区的字节被写入到目的地write(byte[] b):将 b.length个字节从指定的字节数组写入此输出流write(byte[] b, int off, int len):从指定的字节数组写入len字节到此输出流,从偏移量off开始
FileOutputStream类
new FileOutputStream(filename, true);
// true表示追加append,缺省默认false覆盖字节输入流(InputStream)
java.io.InputStream 是字节输入流的超类(父类),它的一些共性方法:
close():关闭此输入流并释放与此流相关的系统资源。int read(): 从输入流读取数据的下一个字节。read(byte[] b): 该方法返回的int值代表的是读取了多少个字节,读取不到返回-1
FileInputStream类
字节流解决中文乱码问题
// 使用 new String(byte bytes[], int offset, int length) 将字节流转换为字符串
try (FileInputStream inputStream = new FileInputStream("a.txt")) {
byte[] bytes = new byte[1024];
int len;
while ((len = inputStream.read(bytes)) != -1) {
System.out.print(new String(bytes, 0, len));
}
}
// String类的构造方法有解码功能
public String(byte bytes[], int offset, int length) {
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(bytes, offset, length);
}
// 默认UTF-8编码解码
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
static char[] decode(byte[] ba, int off, int len) {
String csn = Charset.defaultCharset().name();
try {
// use charset name decode() variant which provides caching.
return decode(csn, ba, off, len);
} catch (UnsupportedEncodingException x) {
warnUnsupportedCharset(csn);
}
}==字符流==
字符流以字符为单位读取和写入数据,而不是以字节为单位。常用来处理文本信息
字符流 = 字节流 + 编码表

字符输入流(Reader)
java.io.Reader是字符输入流的超类(父类),它定义了字符输入流的一些共性方法:
close():关闭此流并释放与此流相关的系统资源。read():从输入流读取一个字符。read(char[] cbuf):从输入流中读取一些字符,并将它们存储到字符数组cbuf中
FileReader类
FileReader实现AutoCloseable 接口,因此可使用try-with-resources语句自动关闭资源,避免了手动关闭资源
File textFile = new File("docs/约定.md");
// 给一个 FileReader 的示例
// try-with-resources FileReader
try(FileReader reader = new FileReader(textFile);) {
// read(char[] cbuf)
char[] buffer = new char[1024];
int len;
while ((len = reader.read(buffer, 0, buffer.length)) != -1) {
System.out.print(new String(buffer, 0, len));
}
}字符输出流(Writer)
java.io.Writer 是字符输出流类的超类(父类),可以将指定的字符信息写入到目的地,它定义的一些共性方法:
write(int c)写入单个字节write(char[] cbuf)写入字符数组write(char[] cbuf, int off, int len)写入字符数组的一部分,off为开始索引,len为字符个数write(String str)写入字符串write(String str, int off, int len)写入字符串某一部分,off 指定起始位置,len 指定长度flush()刷新该流的缓冲close()关闭此流,但要先刷新它
FileWriter类
FileWriter内置了缓冲区ByteBuffer,所以如果不关闭输出流,就无法把字符写入到文件中
flush :刷新缓冲区,流对象可以继续使用
close :先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了
IO异常处理
实际开发中建议使用try...catch...finally代码块处理异常部分
或者直接使用try-with-resources的方式
/*
try-with-resources会在try块执行完毕后自动关闭FileWriter对象 fw,不需要手动关闭流。
如果在try块中发生了异常,也会自动关闭流并抛出异常。
因此,使用try-with-resources可以让代码更加简洁、安全和易读
*/
try (FileWriter fw = new FileWriter("fw.txt")) {
// 写出数据
fw.write("...");
} catch (IOException e) {
e.printStackTrace();
}==缓冲流==
Java缓冲流是对字节流和字符流的一种封装,通过在内存中开辟缓冲区来提高I/O操作的效率
缓冲流的工作原理是将数据先写入缓冲区中,当缓冲区满时再一次性写入文件或输出流,或者当缓冲区为空时一次性从文件或输入流中读取一定量的数据。这样可以减少系统的I/O操作次数,提高系统的I/O效率,从而提高程序的运行效率
字节缓冲流
BufferedInputStream(InputStream in):创建一个新的缓冲输入流,注意参数类型为InputStreamBufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流,注意参数类型为OutputStream
传统的Java IO是阻塞模式。字节缓冲流为解决此问题:一次多读点多写点,减少读写的频率,用空间换时间
- 减少系统调用次数
- 减少磁盘读写次数
- 提高数据传输效率
// BufferedInputStream 的 read 方法
public synchronized int read() throws IOException {
if (pos >= count) { // 如果当前位置已经到达缓冲区末尾
fill(); // 填充缓冲区
if (pos >= count) // 如果填充后仍然到达缓冲区末尾,说明已经读取完毕
return -1; // 返回 -1 表示已经读取完毕
}
return getBufIfOpen()[pos++] & 0xff; // 返回当前位置的字节,并将位置加 1
}
// BufferedOutputStream 的 write(byte b[], int off, int len) 方法
public synchronized void write(byte b[], int off, int len) throws IOException {
if (len >= buf.length) { // 如果写入的字节数大于等于缓冲区长度
/* 如果请求的长度超过了输出缓冲区的大小,
先刷新缓冲区,然后直接将数据写入。
这样可以避免缓冲流级联时的问题。*/
flushBuffer(); // 先刷新缓冲区
out.write(b, off, len); // 直接将数据写入输出流
return;
}
if (len > buf.length - count) { // 如果写入的字节数大于空余空间
flushBuffer(); // 先刷新缓冲区
}
System.arraycopy(b, off, buf, count, len); // 将数据拷贝到缓冲区中
count += len; // 更新计数器
}字符缓冲流
BufferedReader(Reader in):创建一个新的缓冲输入流,注意参数类型为Reader。BufferedWriter(Writer out): 创建一个新的缓冲输出流,注意参数类型为Writer。
字符缓冲流的基本方法与普通字符流调用方式一致。特有的方法。
- BufferedReader:
String readLine(): 读一行数据,读取到最后返回null - BufferedWriter:
newLine(): 换行,由系统定义换行符
==转换流==
转换流可以将一个字节流包装成字符流,或者将一个字符流包装成字节流。这种转换通常用于处理文本数据,如读取文本文件或将数据从网络传输到应用程序。解决乱码问题。
InputStreamReader
java.io.InputStreamReader 是Reader类的子类。作用是将字节流(InputStream)转换为字符流(Reader),同时支持指定的字符集编码方式,从而实现字符流与字节流之间的转换
OutputStreamWriter
java.io.OutputStreamWriter 是 Writer的子类,是将字符流转换为字节流,是字符流到字节流的桥梁
通常为了提高读写效率,我们会在转换流上再加一层缓冲流
小结
InputStreamReader 和 OutputStreamWriter 是将字节流转换为字符流或者将字符流转换为字节流。通常用于解决字节流和字符流之间的转换问题,可以将字节流以指定的字符集编码方式转换为字符流,或者将字符流以指定的字符集编码方式转换为字节流。在使用转换流时,需要指定正确的字符集编码方式,否则可能会导致数据读取或写入出现乱码。
==序列流(序列化和反序列化)==
序列化是指将对象转换字节序列(包含对象的数据、对象的类型和对象中存储的属性等信息),以便网络传输或保存到文件中,或者在程序之间传递
反序列化是指将一个字节序列转换为一个对象,以便在程序中使用
一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口,否则会抛出NotSerializableException。 - 该类的所有字段都必须是可序列化的。如果一个字段不需要序列化,则需要使用
transient进行修饰。
ObjectOutputSream
java.io.ObjectOutputStream继承自OutputStream类,可以将序列化后的字节序列写入到文件、网络等输出流中。
// 构造方法接收一个OutputStream对象作为参数,用于将序列化后的字节序列输出到指定的输出流中
ObjectOutputStream(OutputStream out);
// ObjectOutputStream类中用于将对象序列化成字节序列并输出到输出流中的方法,
// 可以处理对象之间的引用关系、继承关系、静态字段和transient字段
writeObject (Object obj);ObjectInputSream
// 创建一个指定InputStream的ObjectInputStream,用于从指定的文件输入流中读取对象并反序列化
ObjectInputStream(InputStream in);Kryo
实际开发中,很少使用JDK自带的序列化和反序列化
- 可移植性差:Java特有的,无法跨语言进行序列化和反序列化。
- 性能差:序列化后字节体积大,增加了传输/保存成本。
- 安全问题:攻击者可以通过构造恶意数据来实现远程代码执行,从而对系统造成严重的安全威胁。
Kryo是一个Java序列化和反序列化库,具有高性能、高效率和易于使用和扩展等特点,有效地解决了JDK自带序列化机制痛点
已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如 Hive、Storm)中广泛使用。
- pom.xml引入依赖
- 创建Kryo对象,并使用
register()方法将对象进行注册 writeObject()方法将 Java 对象序列化为二进制流readObject()方法将二进制流反序列化为Java对象
==序列接口Serailizable==
Serializable接口定义为空,只起到标识作用,说明实现此接口对象是可被序列化,序列化反序列化的操作不需要由它完成
public interface Serializable {}
// ObjectOutputStream的writeObject0()方法
// 判断对象是否为字符串类型,如果是,则调用 writeString 方法进行序列化
if (obj instanceof String) {
writeString((String) obj, unshared);
}
// 判断对象是否为数组类型,如果是,则调用 writeArray 方法进行序列化
else if (cl.isArray()) {
writeArray(obj, desc, unshared);
}
// 判断对象是否为枚举类型,如果是,则调用 writeEnum 方法进行序列化
else if (obj instanceof Enum) {
writeEnum((Enum<?>) obj, desc, unshared);
}
// 判断对象是否为可序列化类型,如果是,则调用 writeOrdinaryObject 方法进行序列化
else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
}
// 如果对象不能被序列化,则抛出 NotSerializableException 异常
else {
if (extendedDebugInfo) {
throw new NotSerializableException(
cl.getName() + "\n" + debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}ObjectOutputStream序列化时依次调用 writeObject()→writeObject0()→writeOrdinaryObject()→writeSerialData()
→invokeWriteObject()→defaultWriteFields()
private void defaultWriteFields(Object obj, ObjectStreamClass desc) throws IOException {
// 获取对象的类,并检查是否可以进行默认的序列化
Class<?> cl = desc.forClass();
desc.checkDefaultSerialize();
// 获取对象的基本类型字段的数量,以及这些字段的值
int primDataSize = desc.getPrimDataSize();
desc.getPrimFieldValues(obj, primVals);
// 将基本类型字段的值写入输出流
bout.write(primVals, 0, primDataSize, false);
// 获取对象的非基本类型字段的值
ObjectStreamField[] fields = desc.getFields(false);
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
desc.getObjFieldValues(obj, objVals);
// 循环写入对象的非基本类型字段的值
for (int i = 0; i < objVals.length; i++) {
// 调用 writeObject0 方法将对象的非基本类型字段序列化写入输出流
try {
writeObject0(objVals[i], fields[numPrimFields + i].isUnshared());
}
// 如果在写入过程中出现异常,则将异常包装成 IOException 抛出
catch (IOException ex) {
if (abortIOException == null) {
abortIOException = ex;
}
}
}
}ObjectInputStream反序列化时依次调用readObject()→readObject0()→readOrdinaryObject()→readSerialData()→defaultReadFields()
private void defaultReadFields(Object obj, ObjectStreamClass desc) throws IOException {
// 获取对象的类,并检查对象是否属于该类
Class<?> cl = desc.forClass();
if (cl != null && obj != null && !cl.isInstance(obj)) {
throw new ClassCastException();
}
// 获取对象的基本类型字段的数量和值
int primDataSize = desc.getPrimDataSize();
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
// 从输入流中读取基本类型字段的值,并存储在 primVals 数组中
bin.readFully(primVals, 0, primDataSize, false);
if (obj != null) {
// 将 primVals 数组中的基本类型字段的值设置到对象的相应字段中
desc.setPrimFieldValues(obj, primVals);
}
// 获取对象的非基本类型字段的数量和值
int objHandle = passHandle;
ObjectStreamField[] fields = desc.getFields(false);
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
// 循环读取对象的非基本类型字段的值
for (int i = 0; i < objVals.length; i++) {
// 调用 readObject0 方法读取对象的非基本类型字段的值
ObjectStreamField f = fields[numPrimFields + i];
objVals[i] = readObject0(Object.class, f.isUnshared());
// 如果该字段是一个引用字段,则将其标记为依赖该对象
if (f.getField() != null) {
handles.markDependency(objHandle, passHandle);
}
}
if (obj != null) {
// 将 objVals 数组中的非基本类型字段的值设置到对象的相应字段中
desc.setObjFieldValues(obj, objVals);
}
passHandle = objHandle;
}static和transient修饰的字段是不会被序列化的
- 序列化保存的是对象的状态,
static修饰的字段属于类的状态,因此序列化不保存static修饰的字段 transient即临时。阻止字段被序列化。所修饰字段在被反序列化后,字段值被设为初始值
==序列化接口Externalizable==
实现 Externalizable 接口
- 新增一个无参构造方法
- 使用
Externalizable进行反序列化时,会调用被序列化类的无参构造方法去创建一个新的对象,然后再将被保存对象的字段值复制过去。否则的话,会抛出异常
- 使用
- 新增两个方法
writeExternal()和``readExternal()。实现Externalizable`接口所必须的
==Externalizable和Serializable区别==
Externalizable和Serializable都是用于实现Java对象的序列化和反序列化的接口
Serializable是Java标准库提供的接口,Externalizable是Serializable的子接口
Serializable接口不需要实现任何方法,只需要将需要序列化的类标记为Serializable即可
Externalizable接口需要实现writeExternal和readExternal两个方法
Externalizable提供了更高的序列化控制能力,可以序列过程中对对象进行自定义处理,如对敏感信息进行加密和解密
序列化ID
- Java虚拟机是否允许反序列化,取决于类路径和功能代码是否一致,以及序列化ID是否一致
serialVersionUID被称为序列化ID,是决定Java对象能否反序列化成功的重要因子。反序列化时Java虚拟机会把字节流中的serialVersionUID与被序列化类中的serialVersionUID进行比较,相同可以反序列化,否则就会抛出序列化版本不一致异常
==transient关键字==
在Serializable中表示该成员变量不参与序列化和反序列化,在Externalizable中不起作用
一个类的有些字段需要序列化,有些字段不需要,比如说用户的一些敏感信息(如密码、银行卡号等),为了安全起见,不希望在网络操作中传输或者持久化到磁盘文件中,那这些字段就可以加上transient关键字
被transient关键字修饰的成员变量在反序列化时会被自动初始化为默认值
小结
被transient修饰,成员变量不再是对象持久化的一部分。反序列化时自动初始化为默认值
transient关键字只能修饰字段,而不能修饰方法和类
一个静态变量(static关键字修饰)不管是否被transient修饰,均不能被序列化
Serializable接口所有的序列化将会自动进行,
Externalizable接口,则需要在writeExternal方法中指定要序列化的字段,与transient关键字修饰无关
==打印流==
打印流具有几个特点:
- 可以自动进行数据类型转换:打印流可以将各种数据类型转换为字符串,并输出到指定的输出流中。
- 可以自动进行换行操作:打印流可以在输出字符串的末尾自动添加换行符,方便输出多个字符串时的格式控制。
- 可以输出到控制台或者文件中:打印流可以将数据输出到控制台或者文件中,方便调试和日志记录
PrintStream类的常用方法包括:
print():输出一个对象的字符串表示形式。println():输出一个对象的字符串表示形式,并在末尾添加一个换行符。printf():使用指定的格式字符串和参数输出格式化的字符串public PrintStream printf(String format, Object... args); /* 转换说明符 %s:输出一个字符串。 %d 或 %i:输出一个十进制整数。 %x 或 %X:输出一个十六进制整数,%x 输出小写字母,%X 输出大写字母。 %f 或 %F:输出一个浮点数。 %e 或 %E:输出一个科学计数法表示的浮点数,%e 输出小写字母 e,%E 输出大写字母 E。 %g 或 %G:输出一个浮点数,自动选择 %f 或 %e/%E 格式输出。 %c:输出一个字符。 %b:输出一个布尔值。 %h:输出一个哈希码(16进制)。 %n:换行符 宽度修饰符 用数字指定输出的最小宽度,如果输出的数据不足指定宽度,则在左侧或右侧填充空格或零。 精度修饰符 用点号(.)和数字指定浮点数或字符串的精度,对于浮点数,指定小数点后的位数,对于字符串,指定输出的字符数。 对齐修饰符 指定输出的对齐方式 减号(-)表示左对齐填充空格 零号(0)表示右对齐并填充零 */
异常处理
==异常处理==
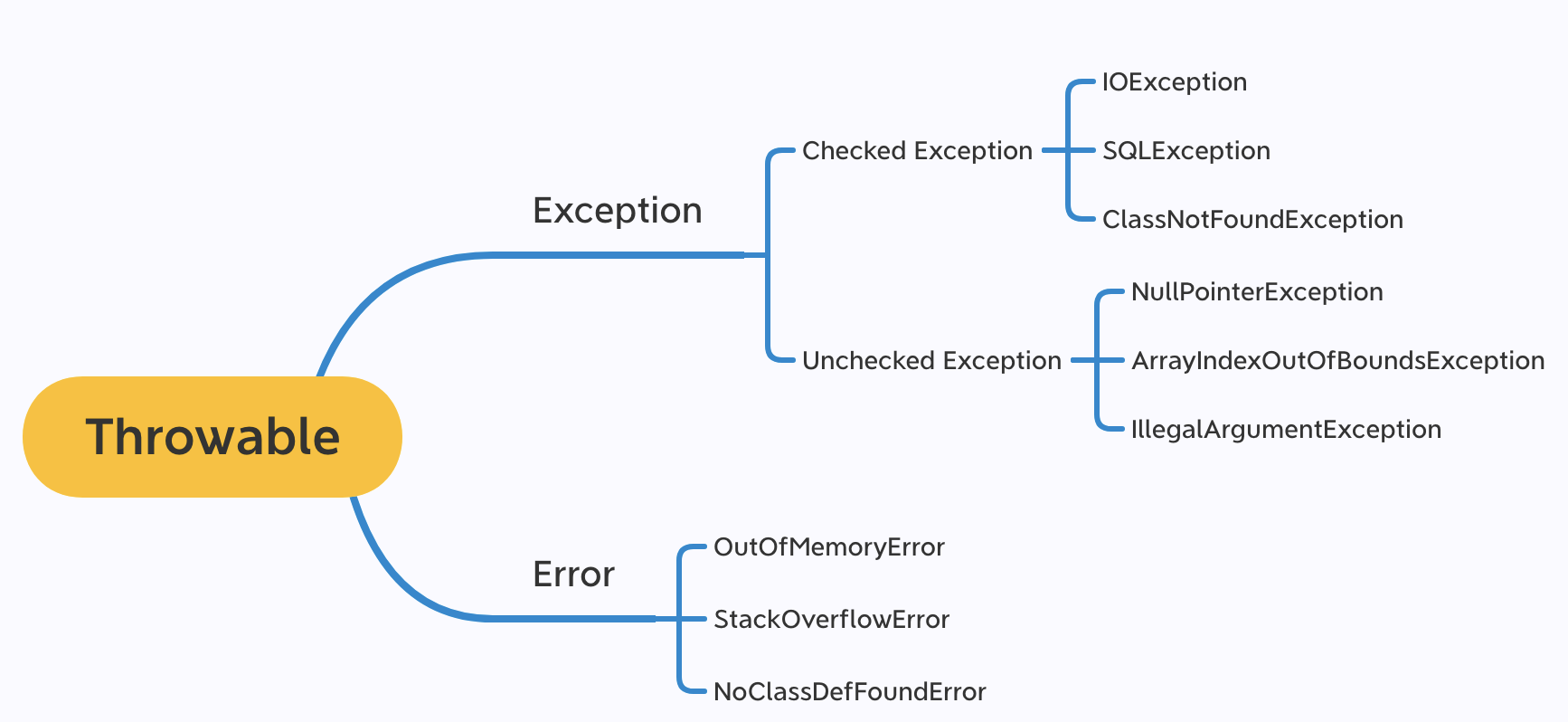
checked异常(检查型异常)在源代码里必须显式地捕获或者抛出,否则编译器会提示进行相应的操作;
unchecked异常(非检查型异常)就是所谓的运行时异常,通常是可以通过编码进行规避的,并不需要显式地捕获或者抛出
NoClassDefFoundError 和 ClassNotFoundException 有什么区别
- NoClassDefFoundError:程序在编译时可以找到所依赖的类,但是在运行时找不到指定的类文件,导致抛出该错误;原因可能是 jar 包缺失或者调用了初始化失败的类。
- ClassNotFoundException:当动态加载 Class 对象的时候找不到对应的类时抛出该异常;原因可能是要加载的类不存在或者类名写错了
throw和throws
- throws关键字用于声明异常,它的作用和try-catch相似;throw关键字用于显式地主动抛出异常
- throws关键字后面跟的是异常的名字;throw 关键字后面跟的是异常的对象
- throws关键字出现在方法签名上,throw关键字出现在方法体里。
- throws关键字在声明异常的时候可以跟多个,用逗号隔开;throw关键字每次只能抛出一个异常
try-catch-finally
finally
- finally块前面必须有try块,不要把finally块单独拉出来使用。编译器不允许这样做
- finally块不是必选项,有try 块的时候不一定要finally块
- 如果finally块中的代码可能会发生异常,也应该使用try-catch进行包裹。
- 即便是try块中执行了return、break、continue这些跳转语句,finally块也会被执行
不执行finally的情况
- 遇到了死循环。
- 执行了
System. exit()
==try-with-resources==
想释放自定义资源的话,只要实现AutoCloseable接口,并提供close()方法即可
==异常处理的20个最佳实践==
- 尽量不要捕获RuntimeException
- 尽量使用try-with-resource关闭资源,禁止在try块中直接关闭资源
- 不要捕获Throwable。Throwable是exception和error的父类
- 不要省略异常信息的记录
- 不要记录了异常又抛出了异常
- 不要在finally块中使用return。try块中的return就将被覆盖
- 抛出具体定义的检查性异常而不是Exception
- 捕获具体的子类而不是捕获Exception类
- 自定义异常时不要丢失堆栈跟踪
- finally块中不要抛出任何异常
- 不要在生产环境中使用
printStackTrace() - 对于不打算处理的异常,直接使用try-finally,不用catch
- 记住早throw晚catch原则。在代码中尽可能早地抛出异常,以便在异常发生时能够及时地处理异常。同时,在catch 块中尽可能晚地捕获异常,以便在捕获异常时能够获得更多的上下文信息,从而更好地处理异常
- 只抛出和方法相关的异常
- 切勿在代码中使用异常来进行流程控制
- 尽早验证用户输入以在请求处理的早期捕获异常
- 一个异常只能包含在一个日志中
- 将所有相关信息尽可能地传递给异常
- 终止掉被中断线程
- 对于重复的try-catch使用模板方法
==空指针==
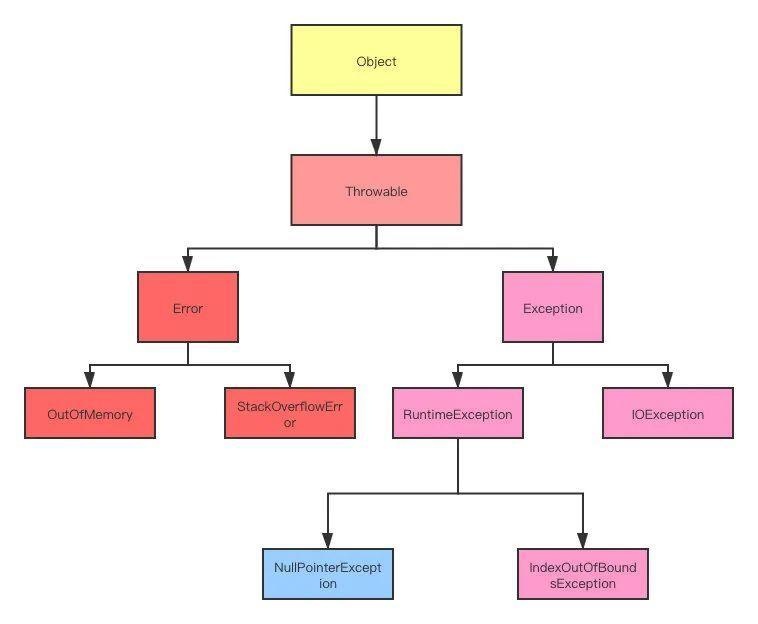
==try-catch会影响性能吗==
try-catch相比较没try-catch确实有一定的性能影响,但是旨在不推荐我们用try-catch来代替正常能不用try-catch的实现,而不是不让用try-catch`。- for循环内用
try-catch和用try-catch包裹整个for循环性能差不多,但是其实两者本质上是业务处理方式的不同,跟性能扯不上关系,关键看业务流程处理。 - 虽然知道
try-catch会有性能影响,但是业务上不需要避讳其使用,业务实现优先(非特殊情况下性能都是其次,有意识地避免大范围的try-catch,只catch 需要的部分即可(没把握全catch 也行,代码安全执行第一)
常用工具类
==Scanner工具类==
Java的Scanner类是一个方便在控制台扫描用户输入的工具类,也可以扫描文件内容(扫描文件可以通过文件流来完成)
提供了多种方法来读取不同类型的数据next(), nextInt(), nextLine(), nextDouble() 等
可以通过 useDelimiter() 方法设置分隔符,通过 findInLine(), findWithinHorizon() 查找匹配项等
==Arrays工具类==
提供了操作数组的静态方法可供直接调用
- 创建数组
copyOf()复制指定的数组,截取或用null填充copyOfRange()复制指定范围内的数组到一个新的数组fill()对数组进行填充
- 比较数组
equals()判断两个数组是否相等
- 数组排序
sort()对数组进行排序- 基本数据类型按双轴快速排序,引用数据类型按TimSort排序,使用了Peter McIlroy的“乐观排序和信息理论复杂性”中的技术
- 数组检索
binarySearch()二分查找
- 数组转流
stream()将数组转换成流
- 打印数组
Arrays.toString()
- 数组转List
Arrays.asList()返回``java.util.Arrays.ArrayList,并不是java.util.ArrayList`,它的长度是固定的,无法进行元素的删除或者添加
setAll()- 为新数组填充基于数组索引的新元素
parallelPrefix()- 通过遍历数组中的元素,将当前下标位置上元素与之前下标元素进行操作,将操作后结果覆盖当前下标位置上元素
==StringUtils工具类==
org.apache.commons.lang3包下的StringUtils工具类
- 字符串判空
isEmpty、isNotEmpty、isBlank和isNotBlank
- 分隔字符串
split避免直接使用String类的split方法可能会出现空指针异常
- 判断是否纯数字
isNumeric - 将集合拼接成字符串
join equals(String str1, String str2):比较两个字符串是否相等equalsIgnoreCase(String str1, String str2):比较两个字符串是否相等,忽略大小写startsWith(String str, String prefix):检查字符串是否以指定的前缀开头endsWith(String str, String suffix):检查字符串是否以指定的后缀结尾contains(String str, CharSequence seq):检查字符串是否包含指定的字符序列capitalize(String str):将字符串的第一个字符转换为大写。uncapitalize(String str):将字符串的第一个字符转换为小写
==Objects工具类==
Objects类的主要目的是降低代码中的空指针异常(NullPointerException) 风险,同时提供一些非常实用的方法
isNull()判断对象是否为空nonNull()判断对象是否不为空requireNonNull()对象为空时,抛出空指针异常Objects.equals()可以处理null值比较,不会抛出空指针异常。但依赖于被比较对象的equals()方法实现hashCode()获取某个对象的hashCodecompare()比较两个对象,通常用于自定义排序deepEquals()比较两个数组类型的对象,当对象是非数组的话行为和equals()一致
==Collections工具类==
JDK提供的一个工具类,位于java.util包
- 排序
reverse(List list):反转顺序shuffle(List list):洗牌,将顺序打乱sort(List list):自然升序sort(List list, Comparator c):按照自定义的比较器排序swap(List list, int i, int j):将 i 和 j 位置的元素交换位置
- 查找
binarySearch(List list, Object key):二分查找法max(Collection coll):返回最大元素max(Collection coll, Comparator comp):根据自定义比较器,返回最大元素min(Collection coll):返回最小元素min(Collection coll, Comparator comp):根据自定义比较器,返回最小元素fill(List list, Object obj):使用指定对象填充frequency(Collection c, Object o):返回指定对象出现的次数
- 同步控制
- 提供了多个
synchronizedXxx()方法,返回一个同步对象,从而解决多线程中访问集合时的安全问题 - 已废弃。正确的做法是使用并发包下的
CopyOnWriteArrayList、ConcurrentHashMap
- 提供了多个
- 不可变集合
emptyXxx():制造一个空的不可变集合singletonXxx():制造一个只有一个元素的不可变集合unmodifiableXxx():为指定集合制作一个不可变集合
addAll(Collection<? super T> c, T... elements)往集合中添加元素disjoint(Collection<?> c1, Collection<?> c2)判断两个集合是否没有交集
CollectionUtils:Spring和Apache都有提供的集合工具类
isEmpty判断集合是否为空,isNotEmpty判断集合不为空union()并集intersection()交集disjunction()补集subtract()差集
==Hutool工具类==
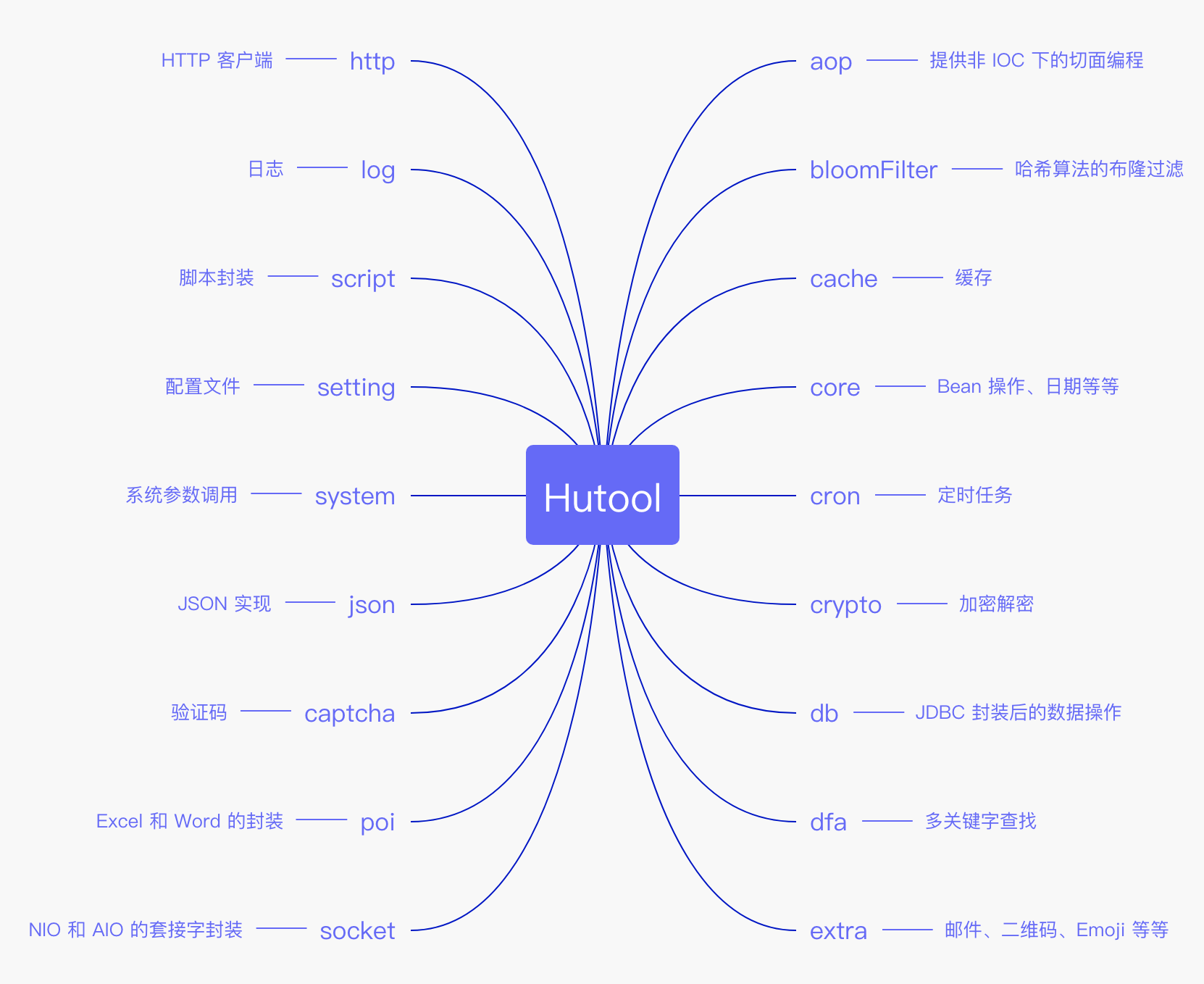
==Guava工具类==
Google公司开源的Java开发核心库
==其他常用工具类==
IpUtil:获取本机Ip
IPUtil 类中定义了两个方法,分别是 getLocalIpByNetcard() 和 getLocalIP()。前者是获取本机的内网 IPv4 地址,避免了返回 127.0.0.1 的问题。后者是获取本地主机地址,如果本机有多个 IP 地址,则可能返回其中的任意一个
MDC:一个线程安全的参数传递工具类
MDC是org.slf4j包下的一个类,它的全称是Mapped Diagnostic Context,我们可以认为它是一个线程安全的存放诊断日志的容器。MDC的底层是用了ThreadLocal 来保存数据的。可以用它传递参数.
能使用MDC保存参数的根本原因是,用户请求到应用服务器,Tomcat 会从线程池中分配一个线程去处理该请求。
该请求的整个过程中,保存到MDC的ThreadLocal中的参数是该线程独享的,所以不会有线程安全问题。
spring的org.springframework.util包下的ClassUtils类
- 获取对象的所有接口
getAllInterfaces - 获取某个类的包名
getPackageName - 判断某个类是否内部类
isInnerClass - 判断对象是否代理对象
isCglibProxy
spring的org.springframework.beans包下的BeanUtils类
- 拷贝对象属性
copyProperties - 反射实例化类
instantiateClass - 获取指定方法
findDeclaredMethod - 获取方法参数
findPropertyForMethod
spring的org.springframework.util包下的ReflectionUtils类
- 获取方法
findMethod - 获取字段
findField - 执行方法
invokeMethod - 判断字段是否常量
isPublicStaticFinal - 判断是否equals方法
isEqualsMethod
Java新特性
==Stream流==
创建流
- 数组
Arrays.stream()或者Stream.of()of()方法内部其实调用了Arrays.stream()方法
- 集合
stream().该方法已经添加到 Collection 接口中 - 集合还可以调用
parallelStream()方法创建并发流,默认使用的是ForkJoinPool.commonPool()线程池。
操作流
- 过滤
filter()从流中筛选出元素。方法接收的是一个Predicate(Java 8新增的一个函数式接口,接受一个输入参数返回一个布尔值结果)类型的参数,因此可以直接将一个Lambda表达式传递给该方法forEach()方法接收的是一个Consumer(Java 8 新增的一个函数式接口,接受一个输入参数并且无返回的操作)类型的参数
- 映射
map()方法接收的是一个Function(Java 8 新增的一个函数式接口,接受一个输入参数T,返回一个结果 R)类型的参数。通过某种操作把一个流中的元素转化成新的流中的元素
- 匹配
anyMatch()只要有一个元素匹配传入的条件,返回true。allMatch()只有有一个元素不匹配传入的条件,返回false;如果全部匹配,则返回truenoneMatch()只要有一个元素匹配传入的条件,返回false;如果全部不匹配,则返回true
- 组合
reduce()主要作用是把 Stream中的元素组合起来Optional<T> reduce(BinaryOperator<T> accumulator)运算规则;返回OptionalT reduce(T identity, BinaryOperator<T> accumulator)T类型起始值,运算规则;返回T类型
转换流
把流转成集合或者数组
toArray() collect() map() toList() toCollection()
==Optional==
Optional可以解决NullPointerException(NPE)问题
创建Optional对象
// 创建空的Optional对象
Optional<String> empty = Optional.empty();
// 创建非空的Optional对象
Optional<String> opt = Optional.of("...");
// 创建一个即可空又可非空的Optional对象
/*
ofNullable() 方法内部有一个三元表达式,参数为null返回私有常量 EMPTY;
否则使用new关键字创建了新的Optional对象——不会再抛出NPE异常
*/
String name = null;
Optional<String> optOrNull = Optional.ofNullable(name);判断值是否存在
// 判断一个Optional对象是否存在,存在返回true,否则返回false
// 取代了obj != null的判断
isPresent();
isEmpty(); // !isPresent();允许使用函数式编程执行代码
ifPresent()ifPresentOrElse(action, emptyAction)
设置(获取)默认值
orElse()方法用于返回包裹在Optional对象中的值,值不为null则返回;否则返回默认值。参数类型和值类型一致orElseGet()与orElse()方法类似,但参数类型不同。值为null执行参数中的函数get()若Optional对象值为null,该方法会抛出NoSuchElementException异常。不推荐使用
==Lambda表达式==
Lambda表达式描述了一个代码块(或者叫匿名方法),可以将其作为参数传递给构造方法或者普通方法以便后续执行
通过 @FunctionalInterface 标记的接口可以通过Lambda表达式创建实例
Lambda语法
( parameter-list ) -> { expression-or-statements }
// () 中的 parameter-list 是以逗号分隔的参数。
// 可以指定或不指定参数类型(编译器会根据上下文进行推断)。Java 11后,可以使用var关键字作为参数类型
// -> 相当于Lambda的标识符
// {} 中的 expression-or-statements为Lambda的主体,可以是一行语句,也可以多行和匿名内部类一样,不要在 Lambda 表达式主体内对方法内的局部变量进行修改,否则编译也不会通过
Lambda表达式中使用且未在Lambda表达式中声明的变量必须声明为final或是effectively final的
Lambda和this关键字
Lambda表达式并不会引入新的作用域,这一点和匿名内部类是不同的。Lambda表达式主体内使用的this关键字和其所在的类实例相同
==Java 14新特性==
instanceof
public class NewInstanceOf {
public static void main(String[] args) {
Object str = "...";
if (str instanceof String s) {
System.out.println(s.length());
}
}
}Records
类的不可变性
- 于Records来说,一条Record就代表一个不变的状态。尽管它会提供诸如
equals()、hashCode()、toString()、构造方法,以及字段的getter,但它无意替代可变对象的类(没有setter),以及Lombok提供的功能
public final class Writer {
private final String name;
private final int age;
public Writer(String name, int age) {
this.name = name;
this.age = age;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
}
public record Writer(String name, int age) { }switch表达式
支持return和函数式表达式
Text Blocks
前后三个英文双引号表示文本块避免多行大量字符串加号拼接
网络编程
==计算机网络==
网络
IP地址
域名
网络模型
常用协议
==套接字Socket==
套接字(Socket)是一个抽象层,应用程序可以通过它发送或接收数据;像操作文件那样可以打开、读写和关闭。套接字允许应用程序将 I/O 应用于网络中,并与其他应用程序进行通信。网络套接字是 IP 地址与端口的组合
ping&telnet
ping,一种计算机网络工具,用来测试数据包能否透过IP协议到达特定主机。ping会向目标主机发出一个ICMP的请求回显数据包,并等待接收回显响应数据包
telnet,Internet远程登录服务的标准协议和主要方式,可以让本地登录到另一台远程计算机。telnet在格外重视安全的现代网络技术中并不受到重用。因为telnet是明文传输协议,用户所有内容(包括用户名和密码)都没有经过加密,安全隐患大
Socket实例
Socket socket = new Socket(host, port);
socket.setSoTimeout(10000); // 单位为毫秒 设置建立超时时间
// 通过java.net.Socket类的getInputStream()方法获取输入流
InputStream is = socket.getInputStream();
Scanner scanner = new Scanner(is, "gbk");
while (scanner.hasNextLine()) {
String line = scanner.nextLine();
System.out.println(line);
}ServerSocket实例
ServerSocket server = new ServerSocket(8888);
// 调用 ServerSocket 对象的 accept() 等待客户端套接字的连接请求。
// 一旦监听到客户端套接字请求,就会返回一个表示连接已建立的Socket对象,可以从中获取到输入流和输出流
Socket socket = server.accept();
InputStream is = socket.getInputStream();
OutputStream os = socket.getOutputStream();
// 向客户端发送消息
PrintWriter pw = new PrintWriter(new OutputStreamWriter(os, "gbk"), true);
pw.println("...");
// 读取客户端信息
Scanner scanner = new Scanner(is);
boolean done = false;
while (!done && scanner.hasNextLine()) {
String line = scanner.nextLine();
System.out.println(line);
if ("完成".equals(line)) {
done = true;
}
}为多个客户端服务
try (ServerSocket server = new ServerSocket(8888)) {
while (true) {
Socket socket = server.accept();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 套接字处理程序
}
});
thread.start();
}
} catch (IOException e) {
e.printStackTrace();
}多线程
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
public class MultiThreadedServer {
public static void main(String[] args) throws IOException {
int port = 12345;
ServerSocket serverSocket = new ServerSocket(port);
System.out.println("Server is listening on port " + port);
while (true) {
Socket socket = serverSocket.accept();
System.out.println("Client connected");
new ClientHandler(socket).start();
}
}
}
/*
使用了一个 ClientHandler类,该类继承自Thread类。这使得每个客户端连接都可以在单独的线程中处理,从而允许服务器同时处理多个客户端连接。当一个新客户端连接到服务器时,服务器会创建一个新的ClientHandler对象,并使用start()方法启动线程。ClientHandler类的run()方法包含处理客户端请求的逻辑
*/
class ClientHandler extends Thread {
private Socket socket;
public ClientHandler(Socket socket) {
this.socket = socket;
}
public void run() {
try {
InputStream input = socket.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
OutputStream output = socket.getOutputStream();
PrintWriter writer = new PrintWriter(output, true);
String line;
while ((line = reader.readLine()) != null) {
System.out.println("Received: " + line);
writer.println("Server: " + line);
}
socket.close();
} catch (IOException e) {
System.out.println("Client disconnected");
}
}
}DatagramSocket实例
DatagramSocket 类是Java中实现UDP协议的核心类。与基于TCP的Socket和ServerSocket类不同,DatagramSocket 类提供了无连接的通信服务,发送和接收数据包。由于无需建立连接,UDP通常比TCP 更快,但不如TCP可靠
// 服务器端代码
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class UDPServer {
public static void main(String[] args) throws IOException {
int port = 12345;
DatagramSocket serverSocket = new DatagramSocket(port);
System.out.println("Server is listening on port " + port);
byte[] buffer = new byte[1024];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
// 阻塞,直到收到一个数据包
serverSocket.receive(packet);
String message = new String(packet.getData(), 0, packet.getLength());
System.out.println("Received: " + message);
serverSocket.close();
}
}
// 客户端代码
import java.io.IOException;
import java.net.*;
public class UDPClient {
public static void main(String[] args) throws IOException {
String hostname = "localhost";
int port = 12345;
InetAddress address = InetAddress.getByName(hostname);
DatagramSocket clientSocket = new DatagramSocket();
String message = "Hello, server!";
byte[] buffer = message.getBytes();
DatagramPacket packet = new DatagramPacket(buffer, buffer.length, address, port);
// 发送数据包
clientSocket.send(packet);
System.out.println("Message sent");
clientSocket.close();
}
}==用Socket实现一个HTTP服务器==
HTTP
HTTP请求消息
请求行(Request Line)
// HTTP方法 请求目标URL HTTP版本 GET /index.html HTTP/1.1请求头(Request Headers)
// 一系列以键值对表示的元数据,用于描述请求的附加信息。每个请求头占一行,键和值之间用冒号(:)分隔 Host: www.tobebetterjavaer.com User-Agent: Mozilla/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8空行(Empty Line)
请求头和请求体间有一个空行,表示请求头的结束
请求体(Request Body,可选)
HTTP响应消息
- 状态行(Status Line)
- 响应头(Response Headers)
- 响应体(Response Body)
NIO
==NIO&OIO==
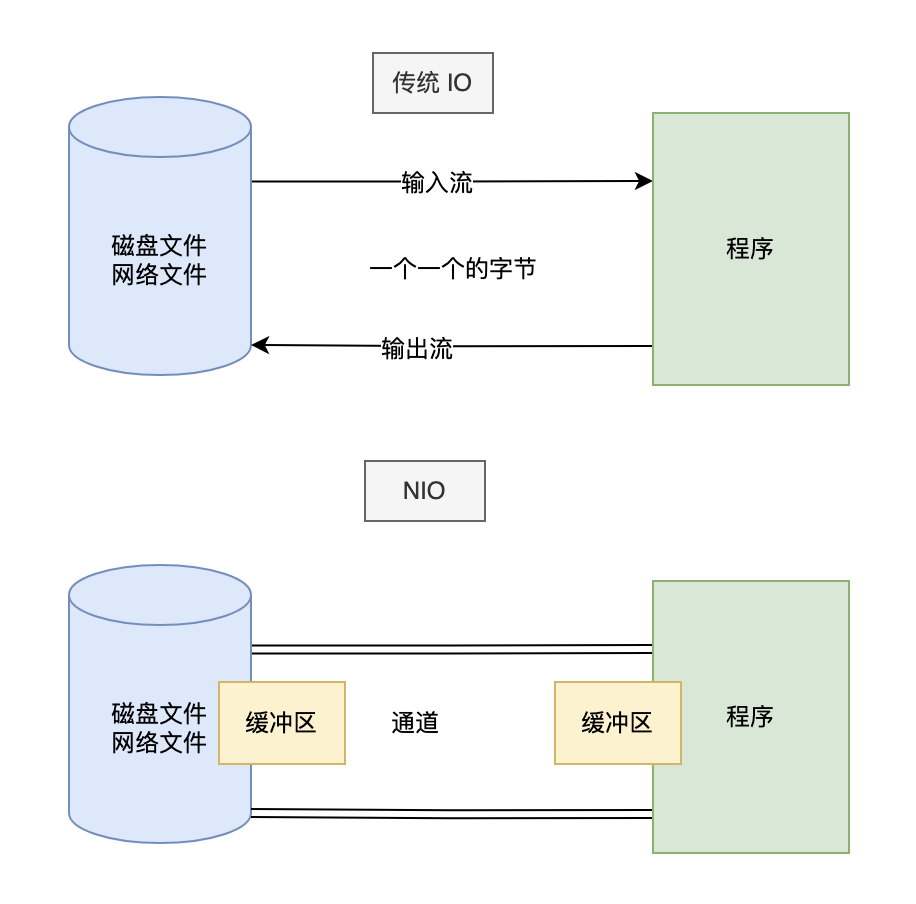
传统IO基于字节流或字符流进行文件读写,以及使用Socket和ServerSocket进行网络传输。
NIO使用通道Channel和缓冲区Buffer进行文件操作,以及使用SocketChannel和ServerSocketChannel进行网络传输
传统IO采用阻塞式模型,对于每个连接,都需要创建一个独立的线程来处理读写操作。当一个线程在等待I/O操作时,无法执行其他任务。这会导致大量线程的创建和销毁,以及上下文切换,降低了系统性能。
NIO使用非阻塞模型,允许线程在等待I/O时执行其他任务。这种模式通过使用选择器(Selector)来监控多个通道Channel上的I/O事件,实现了更高的性能和可伸缩性
NIO和OIO在操作文件时的差异
NIO和OIO在网络传输中的差异
NIO的设计目标是解决传统I/O(BIO,Blocking I/O)在处理大量并发连接时的性能瓶颈。传统 I/O 在网络通信中主要使用阻塞式 I/O,为每个连接分配一个线程。当连接数量增加时,系统性能将受到严重影响,线程资源成为关键瓶颈。而 NIO 提供了非阻塞 I/O 和 I/O 多路复用,可以在单个线程中处理多个并发连接,从而在网络传输中显著提高性能。
NIO在网络传输中优于传统I/O的原因:
①、NIO支持非阻塞I/O,这意味着在执行I/O操作时,线程不会被阻塞。使得网络传输中可以有效管理大量并发连接
操作文件时,优势不明显,因为文件读写通常不涉及大量并发操作。
②、NIO支持I/O多路复用,一个线程可以同时监视多个通道(如套接字),在I/O事件(如可读、可写)准备好时处理。这大大提高了网络传输中的性能,因为单个线程可以高效地管理多个并发连接。操作文件时该优势无法提现出来。
③、NIO提供了ByteBuffer类,可以高效地管理缓冲区。在网络传输中很重要,因为数据通常是以字节流的形式传输。操作文件的时候,虽然也有缓冲区,但优势仍然不够明显
NIO网络编程
ServerSocketChannel 类似于ServerSocket,表示服务器端套接字通道。它负责监听客户端连接请求,
可以设置为非阻塞模式,这意味着在等待客户端连接请求时不会阻塞线程。
SocketChannel 类似于Socket,表示客户端套接字通道。它负责与服务器端建立连接并进行数据的读写。SocketChannel也可以设置为非阻塞模式,在读写数据时不会阻塞线程
Selector是Java NIO中的一个关键组件,用于实现I/O多路复用。它允许在单个线程中同时监控多个 ServerSocketChannel和SocketChannel,并通过SelectionKey标识关注的事件。当某个事件发生时,Selector 会将对应的SelectionKey 添加到已选择的键集合中。通过使用Selector,可以在单个线程中同时处理多个连接,从而有效地提高I/O操作的性能,特别是在高并发场景下
小结
传统I/O采用阻塞式模型,线程在I/O操作期间无法执行其他任务。
NIO非阻塞模型,允许线程在等待I/O时执行其他任务,通过Selector监控多个ChannelI/O事件,提高性能和可伸缩性
传统I/O使用基于字节流或字符流的类进行文件读写。
NIO使用通道(Channel)和缓冲区(Buffer)进行文件操作,NIO在性能上的优势并不大。
传统I/O使用Socket和ServerSocket进行网络传输,存在阻塞问题。
NIO 提供了SocketChannel和ServerSocketChannel,支持非阻塞网络传输,提高了并发处理能力
IO 是面向流的处理,NIO 是面向块(缓冲区)的处理
传统IO流是单向的。NIO通道读写是双向的
==Java IO与BIO、NIO==
IO,是Input/Output的简称,即输入/输出。通常指数据在内存和外部存储器或其他周边设备之间的输入和输出
三种IO
BIO
BIO全称Block-IO一种同步且阻塞的通信模式。较传统的通信方式,模式简单,使用方便。
但并发处理能力低,通信耗时,依赖网速
NIO
- Java NIO,Non-Block IO,Java SE 1.4版后针对网络传输效能优化的新功能。一种非阻塞同步的通信模式。
AIO
Java AIO,Asynchronous IO,异步非阻塞的IO。是一种非阻塞异步的通信模式
在NIO的基础上引入了新的异步通道的概念,并提供了异步文件通道和异步套接字通道的实现
三种IO的区别
BIO (Blocking I/O) 同步阻塞I/O模式
BIO方式适用于连接数目比较小且固定的架构,
这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择,但程序直观简单易理解
NIO (New I/O) 同步非阻塞模式
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,
比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4 开始支持
AIO (Asynchronous I/O):异步非阻塞I/O模型
AIO 方式适用于连接数目多且连接比较长(重操作)的架构,
比如相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK7 开始支持
小结
BIO(Blocking I/O) 采用阻塞式I/O 模型,线程在执行I/O操作时被阻塞,无法处理其他任务,
适用于连接数较少且稳定的场景。
NIO(New I/O 或 Non-blocking I/O) 使用非阻塞I/O模型,线程在等待I/O时可执行其他任务
通过Selector监控多个Channel上的事件,提高性能和可伸缩性,适用于高并发场景。
AIO(Asynchronous I/O) 采用异步I/O模型,线程发起I/O请求后立即返回,
当I/O操作完成时通过回调函数通知线程,进一步提高了并发处理能力,适用于高吞吐量场景
==NIO的Buffer和Channel==
NIO通过Channel通道运输着存储数据的Buffer缓冲区实现数据处理
Buffer缓冲区
Buffer是缓冲区的抽象类。核心方法就是put和get
Buffer类维护了4个核心变量来提供关于其所包含的数组信息。它们是:
- 容量 Capacity 缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定且永远不能被改变(底层是数组)
- 上界 Limit 缓冲区里的数据的总数,代表了当前缓冲区中一共有多少数据
- 位置 Position 下一个要被读或写的元素的位置。Position会自动由相应的get()和put()函数更新
- 标记 Mark 一个备忘位置。用于记录上一次读写信息
flip() 改动position和limit的位置
clear() 清空缓冲区,数据没有真正被清空,只是被遗忘
Channel通道
Channel 通道只负责传输数据、不直接操作数据
文件通道
FileChannel
用于文件 I/O 的通道,支持文件的读写和追加操作。FileChannel允许在文件的任意位置进行数据传输,支持文件锁定以及内存映射文件等高级功能。FileChannel无法设置为非阻塞模式,因此它只适用于阻塞式文件操作
套接字通道
SocketChannel / ServerSocketChannel
用于TCP套接字I/O的通道。SocketChannel支持非阻塞模式,可以与Selector一起使用,实现高效的网络通信。SocketChannel允许连接到远程主机,进行数据传输
DatagramChannel
用于 UDP 套接字 I/O 的通道。DatagramChannel 支持非阻塞模式,可以发送和接收数据报包,适用于无连接的、不可靠的网络通信。
==Paths和Files==
Paths和Files在Java 7的时候引入,作为对java.io.File类的补充和改进
Paths类
Files类
==Java IO模型==
阻塞IO和非阻塞IO
阻塞I/O(Blocking I/O):I/O操作是阻塞的,即执行I/O操作时,线程会被阻塞,直到操作完成。在阻塞I/O模型中,每个连接都需要一个线程来处理。因此,对于大量并发连接的场景,阻塞 I/O 模型的性能较差
非阻塞I/O(Non-blocking I/O):I/O操作不会阻塞线程。当数据尚未准备好时,I/O调用会立即返回。线程可以继续执行其他任务,然后在适当的时候再次尝试执行I/O操作。非阻塞I/O模型允许单个线程同时处理多个连接,但可能需要在应用程序级别进行复杂的调度和管理
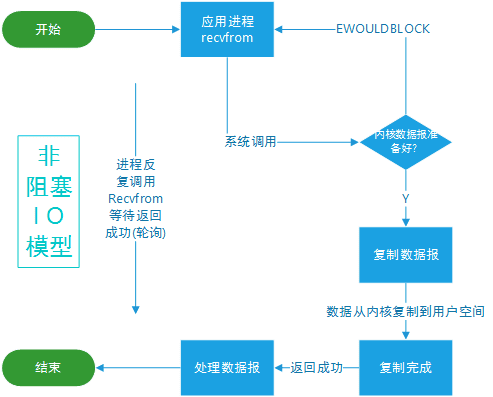
多路复用
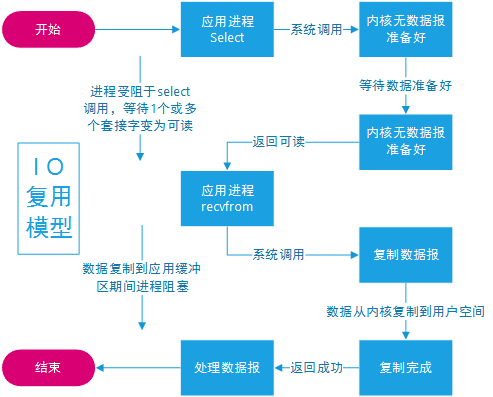
I/O多路复用(I/O Multiplexing)模型使用操作系统提供的多路复用功能(如 select、poll、epoll 等),使得单个线程可以同时处理多个I/O事件。当某个连接上的数据准备好时,操作系统会通知应用程序。这样,应用程序可以在一个线程中处理多个并发连接,而不需要为每个连接创建一个线程
- select是 Unix系统中最早的 I/O 多路复用技术。它允许一个线程同时监视多个文件描述符(如套接字),并等待某个文件描述符上的 I/O 事件(如可读、可写或异常)。select的主要问题是性能受限,特别是在处理大量文件描述符时。因为它使用一个位掩码来表示文件描述符集,每次调用都需要传递这个掩码,并在内核和用户空间之间进行复制。
- poll是对select的改进。它使用一个文件描述符数组而不是位掩码表示文件描述符集。可以避免select的性能问题。然而,poll仍需遍历整个文件描述符数组以检查每个文件描述符的状态。因此在处理大量文件描述符时性能仍然受限。
- epoll是Linux 中的一种高性能I/O多路复用技术。它通过在内核中维护一个事件表来避免遍历文件描述符数组的性能问题。当某个文件描述符上的I/O事件发生时,内核会将该事件添加到事件表中。应用程序可以使用epoll_wait函数来获取已准备好的I/O事件,而无需遍历整个文件描述符集。这种方法大大提高了在大量并发连接下的性能。
在JavaNIO 中,I/O多路复用主要通过 Selector 类实现。Selector 能够监控多个Channel上的I/O事件,如连接、读取和写入。这使得一个线程可以处理多个并发连接,提高了程序的性能和可伸缩性。
信号驱动

信号驱动 I/O(Signal-driven I/O)模型中,应用程序可以向操作系统注册一个信号处理函数,当某个I/O事件发生时,操作系统会发送一个信号通知应用程序。应用程序在收到信号后处理相应的I/O事件。这种模型与非阻塞I/O类似,也需要在应用程序级别进行事件管理和调度。
异步IO
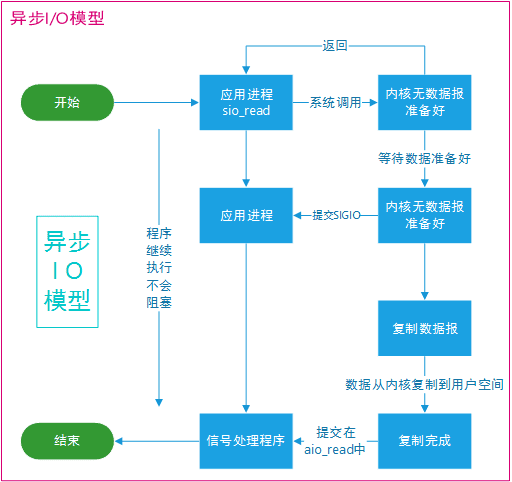
异步I/O(Asynchronous I/O)模型与同步 I/O模型的主要区别在于,异步I/O操作会在后台运行,当操作完成时,操作系统会通知应用程序。应用程序不需要等待I/O操作的完成,可以继续执行其他任务。这种模型适用于处理大量并发连接,且可以简化应用程序的设计和开发。
- 同步:在执行I/O操作时,应用程序需要等待操作的完成。同步操作会导致线程阻塞,直到操作完成。同步I/O包括阻塞 I/O、非阻塞I/O和I/O多路复用。
- 异步:在执行I/O操作时,应用程序不需要等待操作的完成。异步操作允许应用程序在I/O操作进行时继续执行其他任务。异步I/O模型包括信号驱动I/O和异步I/O。
小结
IO模型主要有五种:阻塞 I/O、非阻塞I/O、多路复用、信号驱动和异步I/O。
- 阻塞I/O:应用程序执行I/O操作时,会一直等待数据传输完成,期间无法执行其他任务。
- 非阻塞I/O:应用程序执行I/O操作时,如果数据未准备好立即返回错误状态,不等待数据传输完成可执行其他任务。
- 多路复用:允许一个线程同时管理多个I/O连接,适用于高并发低延迟高吞吐量场景,减少线程数量和上下文切换开销。
- 信号驱动:依赖信号通知应用程序I/O事件,用于低并发低延迟低吞吐量场景,需为各I/O事件创建信号、信号处理函数
- 异步I/O:应用程序发起I/O操作后,内核负责数据传输过程完成后通知应用程序。应用程序无需等待,可执行其他任务
Java重要知识点
==Java命名规范==
包
- 小写
- 点分隔符间有且仅有一个自然语义单词
- 包名统一使用单数形式
- 域名反写
类
- 大写开头
- 名词
- 驼峰式命名UpperCamelCase风格
- 抽象类 Abstract或Base开头
- 异常类 Exception结尾
- 测试类 Test结尾
接口
- 大写开头
- 形容词
- 实现 able->tor 或 Impl
字段和变量
- 小写开头的驼峰式命名 upperCamelCase
- POJO类boolean型变量不加is前缀,避免部分框架解析产生的序列化错误(如fastjson)
- 避免在子类和父类的成员变量之间、或者不同代码块的局部变量之间采用完全相同的命名
常量
- 大写
- _连接
- 可包含数字,不以数字开头
方法
- 小写开头的驼峰式风格
- 动词
其他
均不以下划线或美元符号开始
方法名、参数名、成员变量、局部变量都统一使用lowerCamelCase风格
模块、接口、类、方法使用了设计模式,在命名时需体现出具体模式
枚举类名带上Enum后缀,枚举成员名称需要全大写,单词间用下划线隔开。
枚举其实就是特殊的常量类,且构造方法被默认强制是私有
==中文乱码问题及字符编码==
常见的字符编码
- ASCII
- 局限在于只能显示 26 个基本拉丁字母、阿拉伯数字和英式标点符号
- Unicode 万国码、国际码、统一码、单一码
- UTF-8
- 可变长度的编码方式
- UTF-16
- UTF-8
- GB2312
==拆箱和装箱==
拆箱就是将包装类型对象转换为其对应的基本数据类型,装箱则是将基本数据类型转换为相应的包装类型对象
包装类型和基本数据类型的区别
包装类型可以为null,基本数据类型不可以
数据库查询结果可能是null,如果使用基本数据类型,自动拆箱会抛出NullPointerException的异常
包装类型可用于泛型,基本数据类型不可以
泛型在编译时会进行类型擦除,最后只保留原始类型.原始类型只能是Object类及其子类:基本数据类型是例外
基本数据类型比包装类型更高效
- 包装类型要存储对象和引用,需要占用更多的内存空间
两个包装类型的值可以相同,但却不相等
自动拆箱和自动装箱
自动装箱是通过 Integer.valueOf() 完成的;自动拆箱是通过 Integer.intValue() 完成的
当需要进行自动装箱时,如果数字在-128至127之间时,会直接使用缓存中的对象,而不是重新创建一个对象
==Java浅拷贝与深拷贝==
clone()
浅拷贝和深拷贝都可以通过调用Object类的clone()方法来完成
clone()方法是一个本地(native)方法,它的具体实现会交给 HotSpot 虚拟机,那就意味着虚拟机在运行该方法的时候,会将其替换为更高效的 C/C++ 代码,进而调用操作系统去完成对象的克隆工作。Java 9后,该方法会被标注 @HotSpotIntrinsicCandidate注解,被该注解标注的方法在 HotSpot 虚拟机中会有一套高效的实现
实现Cloneable接口标记类可以执行clone()方法
public interface Cloneable {
}浅拷贝克隆的对象中,引用类型的字段指向的是同一个,当改变任何一个对象,另外一个对象也会随之改变
深拷贝中的引用类型字段也会克隆一份,当改变任何一个对象,另外一个对象不会随之改变
通过clone()方法实现深拷贝要将所有的引用类型都重写clone()方法
序列化/反序列化
由于是序列化涉及到输入流和输出流的读写,在性能上要比HotSpot虚拟机实现的clone()方法差很多
==Java hashCode方法解析==
// Object类包含hashCode()方法
// Java 9后,hashCode() 方法被@HotSpotIntrinsicCandidate注解修饰,
// 表明在HotSpot虚拟机中有基于CPU指令高效的实现
public native int hashCode();在Java中,hashCode()方法是定义在 java.lang.Object 类中的一个方法,该类是所有 Java 所有类的父类。因此,每个 Java 对象都可以调用 hashCode()方法。hashCode()方法主要用于支持哈希表(如 java.util.HashMap),这些数据结构使用哈希算法能实现快速查找、插入和删除操作。
hashCode()方法的主要目的是返回一个整数,这个整数称为哈希码,它代表了对象在内存中的一种近似表示。哈希码用于将对象映射到哈希表中的一个特定的位置。两个相等的对象(根据 equals()方法比较)应该具有相同的哈希码。然而,具有相同哈希码的两个对象并不一定相等
当你创建一个自定义类并覆盖equals()方法时,通常也需要覆盖hashCode()方法,以确保相等的对象具有相同的哈希码。这有助于提高哈希表在使用自定义类的对象作为键时的准确性。
==Java值传递与引用传递==
- Java中的参数传递是按值传递的。
- 如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
- 如果参数是引用类型,传递的是引用的对象在堆中地址的拷贝
==Java为什么无法实现真正的泛型==
- 兼容性
- 类型擦除实现了兼容性,Java 1.5之后的类可以使用泛型,而 Java 1.4之前没有使用泛型的类也可以保留,并且不用做任何修改就能在新版本的Java虚拟机上运行
- Pizza实现了真正的泛型:基本数据类型+包装器类型
==Java反射==
反射
- 优点
- 开发通用框架:像Spring,为了保持通用性,通过配置文件来加载不同的对象,调用不同的方法。
- 动态代理:在面向切面编程中,需要拦截特定的方法会选择动态代理的方式,而动态代理的底层技术就是反射。
- 注解:注解本身只是起到一个标记符的作用,它需要利用发射机制,根据标记符去执行特定的行为。
- 缺点
- 破坏封装:由于反射允许访问私有字段和私有方法,所以可能会破坏封装而导致安全问题。
- 性能开销:由于反射涉及到动态解析,因此无法执行Java虚拟机优化,加上反射的写法的确要复杂得多,所以性能差,在一些性能敏感的程序中应该避免使用反射
获取Class对象
// 通过类的全名获取 Class 对象
Class clazz = Class.forName("com.itwanger.s39.Writer");
// 通过调用实例的getClass()方法获取 Class 对象
String str = "Hello World";
Class cls = str.getClass();
// 通过类的字面量(类本身)获取对象
Class cls = String.class通过Class对象获取构造方法Constructor对象
Constructor constructor = clazz.getConstructor();通过Constructor对象初始化反射类对象
Object object = constructor.newInstance();获取要调用的方法的Method对象
Method setNameMethod = clazz.getMethod("setName", String.class);
Method getNameMethod = clazz.getMethod("getName"); 反射访问私有字段和(构造)方法需要使用Constructor/Field/Method.setAccessible(true)绕开Java语言访问限制
invoke() 方法执行
setNameMethod.invoke(object, "...");
getNameMethod.invoke(object)每一个类,不管最终生成了多少个对象,这些对象只会对应一个 Class 对象,这个 Class 对象是由Java虚拟机生成的,由它来获悉整个类的结构信息.java.lang.Class是所有反射API的入口
方法的反射调用,最终是由 Method 对象的 invoke() 方法完成
public Object invoke(Object obj, Object... args)
throws IllegalAccessException, IllegalArgumentException,
InvocationTargetException {
// 如果方法不允许被覆盖,进行权限检查
if (!override) {
if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) {
Class<?> caller = Reflection.getCallerClass();
// 检查调用者是否具有访问权限
checkAccess(caller, clazz, obj, modifiers);
}
}
// 获取方法访问器(从 volatile 变量中读取)
MethodAccessor ma = methodAccessor;
if (ma == null) {
// 如果访问器为空,尝试获取方法访问器
ma = acquireMethodAccessor();
}
// 使用方法访问器调用方法,并返回结果
return ma.invoke(obj, args);
}
// invoke() 方法实际上是委派给 MethodAccessor 接口来完成的
// MethodAccessor 接口有三个实现类
// MethodAccessorImpl是一个抽象类,另外两个具体的实现类继承了这个抽象类
// NativeMethodAccessorImpl:通过本地方法来实现反射调用;
// DelegatingMethodAccessorImpl:通过委派模式来实现反射调用;委派实现
invoke() 方法执行时,先调用DelegatingMethodAccessorImpl,然后调用NativeMethodAccessorImpl,最后再调用实际的方法。采用委派实现,是为了能够在本地实现和动态实现之间切换。动态实现是另外一种反射调用机制,它是通过生成字节码的形式来实现的。如果反射调用的次数比较多,动态实现的效率就会更高,因为本地实现需要经过Java到C/C++再到 Java之间的切换过程,而动态实现不需要;但如果反射调用的次数比较少,反而本地实现更快一些。临界点默认是15次
并发编程
==进程和线程==
- 进程,是对运行时程序的封装,是系统进行资源调度和分配的基本单位,实现了操作系统的并发。
- 线程,是进程的子任务,是CPU调度和分派的基本单位,实现了进程内部的并发。
- 线程在进程下进行
- 进程之间不会相互影响,主线程结束将会导致整个进程结束
- 不同的进程数很难共享
- 同进程下的不同线程之间数据易共享
- 进程使用内存地址可以限定使用量
==创建线程的三种方式==
继承Thread类
// 创建一个类继承Thread类,并重写run方法 public class MyThread extends Thread { @Override public void run() { ...; } }实现Runnable接口
// 创建一个类实现Runnable接口,并重写run方法 public class MyRunnable implements Runnable { @Override public void run() { ...; } }实现Callable接口
// 实现Callable接口,重写call方法,这种方式可以通过FutureTask获取任务执行的返回值 public class CallerTask implements Callable<String> { public String call() throws Exception { return "..."; } public static void main(String[] args) { //创建异步任务 FutureTask<String> task=new FutureTask<String>(new CallerTask()); //启动线程 new Thread(task).start(); try { //等待执行完成,并获取返回结果 String result=task.get(); System.out.println(result); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } }
重写run方法
- 默认的
run()方法不会做任何事情。为了让线程执行实际任务,需要提供run()方法实现
run方法和start方法区别
run():封装线程执行的代码,直接调用相当于调用普通方法start():启动线程,然后由JVM调用此线程的run()方法
通过继承Thread的方法和实现Runnable 接口的方式创建多线程哪个好
- 实现 Runable 接口好,原因有两个:
- 避免了Java单继承的局限性,Java不支持多重继承,因此如果类已经继承了另一个类,就不能再继承Thread类
- 适合多个相同的程序代码去处理同一资源的情况,把线程、代码和数据有效的分离,更符合面向对象的设计思想。Callable接口与Runnable非常相似,但可以返回一个结果
线程控制方法
sleep()使当前正在执行的线程暂停指定毫秒数,进入休眠状态。使用sleep会发生异常要显示处理join()等待该线程执行完才会轮到后续线程得到cpu的执行权。使用join要捕获异常setDaemon()将此线程标记为守护线程,服务其他线程。yield()静态方法,暗示当前线程愿意放弃其当前的时间片,允许其他线程执行。然而,它只是向线程调度器提出建议,调度器可能会忽略这个建议。具体行为取决于操作系统和JVM的线程调度策略。
线程的生命周期
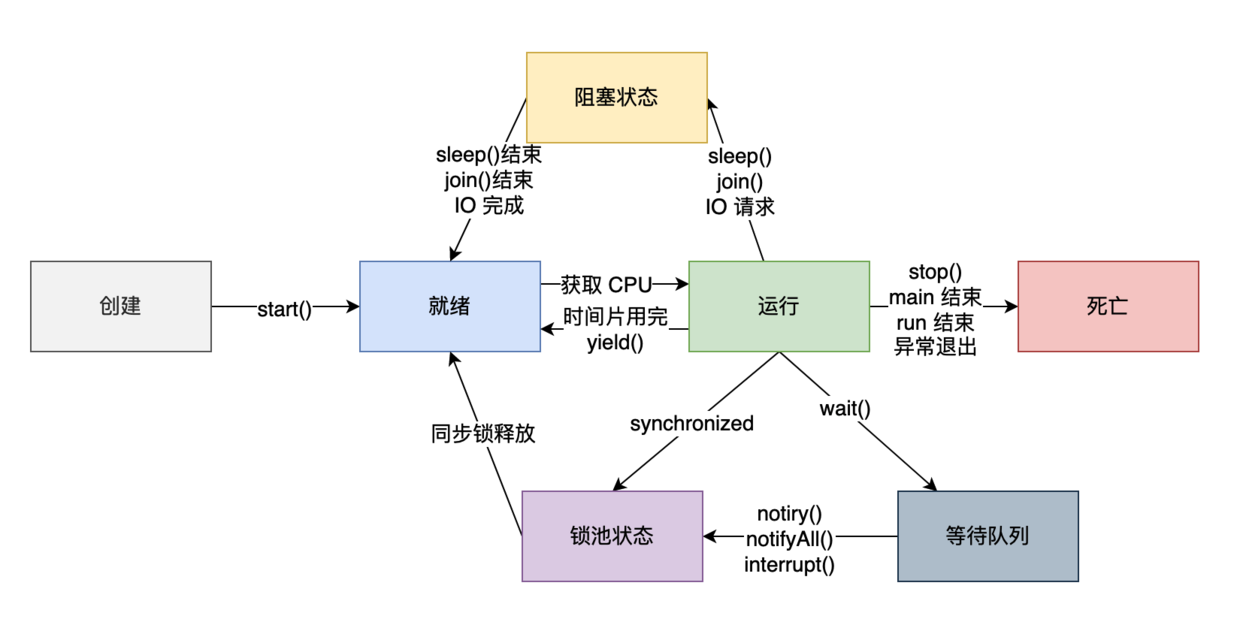
==获取Java线程执行结果==
- 直接继承Thread或实现Runnable接口,重写的run方法返回类型void,无法获取执行结果
- 如果需要获取执行结果,就必须通过共享变量或者线程通信的方式来达到目的,使用起来较麻烦
- Java 1.5提供了Callable、Future、FutureTask,可以在任务执行完后得到执行结果
有返回值的Callable
// Callable接口位于java.util.concurrent包下。定义了一个 call() 方法
public interface Callable<V> {
V call() throws Exception;
}
// Callable一般会配合 ExecutorService使用。
// ExecutorService接口位于java.util.concurrent包下,
// 是Java线程池框架的核心接口,用来异步执行任务。提供了一些关键方法用来进行线程管理异步计算结果Future接口
// Future接口位于java.util.concurrent包下
// 提供三种功能: 判断任务是否完成,中断任务,获取任务执行结果
public interface Future<V> {
// 取消任务
boolean cancel(boolean mayInterruptIfRunning);
// 任务是否被取消成功
boolean isCancelled();
// 任务是否已完成
boolean isDone();
// 获取执行结果。该方法产生阻塞,一直等到任务执行完毕才返回
V get() throws InterruptedException, ExecutionException;
// 获取执行结果。指定时间内未获取返回null
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}异步计算结果FutureTask实现类
public class FutureTask<V> implements RunnableFuture<V>{
public FutureTask(Callable<V> callable) {}
public FutureTask(Runnable runnable, V result) {}
}
// 可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
JVM
== 和 equals()
“==”运算符比较的时候,如果两个对象都为null,并不会发生
NullPointerException,而equals()方法会“==”运算符会在编译时进行检查,如果两侧的类型不匹配会提示错误,而
equals()方法则不会
LinkedList和ArrayDeque
都是Java集合框架中的双向队列(deque),它们都支持在队列的两端进行元素的插入和删除操作。
不过,LinkedList和ArrayDeque在实现上有一些不同:
- 底层实现方式不同:LinkedList是基于链表实现的,而ArrayDeque是基于数组实现的。
- 随机访问的效率不同:由于底层实现方式的不同,LinkedList 对于随机访问的效率较低,时间复杂度为O(n),而 ArrayDeque 可以通过下标随机访问元素,时间复杂度为O(1)。
- 迭代器的效率不同:LinkedList对于迭代器的效率比较低,因为需要通过链表进行遍历,时间复杂度为 O(n),而 ArrayDeque的迭代器效率比较高,因为可以直接访问数组中的元素,时间复杂度为 O(1)。
- 内存占用不同:由于LinkedList 是基于链表实现的,它在存储元素时需要额外的空间来存储链表节点,因此内存占用相对较高,而ArrayDeque 是基于数组实现的,内存占用相对较低。
Java取模和取余
取模运算(Modulo Operation)和取余运算(Remainder Operation)
从严格意义上来讲,是两种不同的运算方式,它们在计算机中的实现也不同。
在Java中,通常使用%运算符来表示取余,用Math.floorMod()来表示取模。
- 当操作数都是正数的话,结果一样
- 只有当操作数出现负数的情况,结果不同。
- 取模运算的商向负无穷靠近;取余运算的商向0靠近。这是导致它们两个在处理有负数情况下结果不同的根本原因。
- 当数组的长度是2的n次方或n次幂或n的整数倍时,取模运算/取余运算可以用位运算来代替,效率更高。
Compator.reverseOrder()
Comparator.reverseOrder()返回的是Collections.ReverseComparator对象,用来反转顺序的,非常方便
private static class ReverseComparator
implements Comparator<Comparable<Object>>, Serializable {
// 单例模式,用于表示逆序比较器
static final ReverseComparator REVERSE_ORDER
= new ReverseComparator();
// 实现比较方法,对两个实现了Comparable接口的对象进行逆序比较
public int compare(Comparable<Object> c1, Comparable<Object> c2) {
return c2.compareTo(c1); // 调用c2的compareTo()方法,以c1为参数,实现逆序比较
}
// 反序列化时,返回Collections.reverseOrder(),保证单例模式
private Object readResolve() {
return Collections.reverseOrder();
}
// 返回正序比较器
@Override
public Comparator<Comparable<Object>> reversed() {
return Comparator.naturalOrder();
}
}Java的四种引用类型
- 强引用(Strong Reference),
- 正常编码时默认的引用类型。如果一个对象到GC Roots强引用可到达,就可以阻止GC回收该对象
- 软引用(Soft Reference)
- 阻止GC回收的能力相对弱一些。软引用可以到达,则该对象会停留在内存更时间上长一些。
- 当内存不足时垃圾回收器才会回收这些软引用可到达的对象
- 弱引用(WeakReference)
- 无法阻止GC回收。弱引用可到达,则在下一个GC回收执行时,该对象就会被回收掉。
- 虚引用(Phantom Reference)
- 十分脆弱。唯一作用是当其指向的对象被回收之后,自己被加入到引用队列,用作记录该引用指向的对象已被销毁
Java引用队列(Reference Queue)
- 一般情况下,一个对象标记为垃圾(并不代表回收)后,会加入到引用队列。
- 对于虚引用来说,它指向的对象会只有被回收后才会加入引用队列,所以可以用作记录该引用指向的对象是否回收。
绝对路径和相对路径
Java中相对路径通常是相对于当前Java程序所在的目录
Windows操作系统中,文件系统默认不区分大小写; macOS和Linux等Unix系统中,文件系统默认是区分大小写
回车符&换行符
回车符(\r)和换行符(\n)用于表示一行结束或者换行的操作。在不同操作系统和编程语言中使用方式可能有所不同
- 在Windows系统中,通常使用回车符和换行符的组合(
\r\n)来表示一行的结束 - 在macOS和Linux系统中,通常只使用换行符(
\n)来表示一行的结束
级联问题(Cascade Problem)
指在一组缓冲流(Buffered Stream)中,由于缓冲区的大小不足以容纳要写入的数据,导致数据被分割成多个部分,并分别写入到不同的缓冲区中,最终需要逐个刷新缓冲区,从而导致性能下降的问题。
字符集
Charset:字符集,是一组字符的集合,每个字符都有一个唯一的编码值,也称为码点
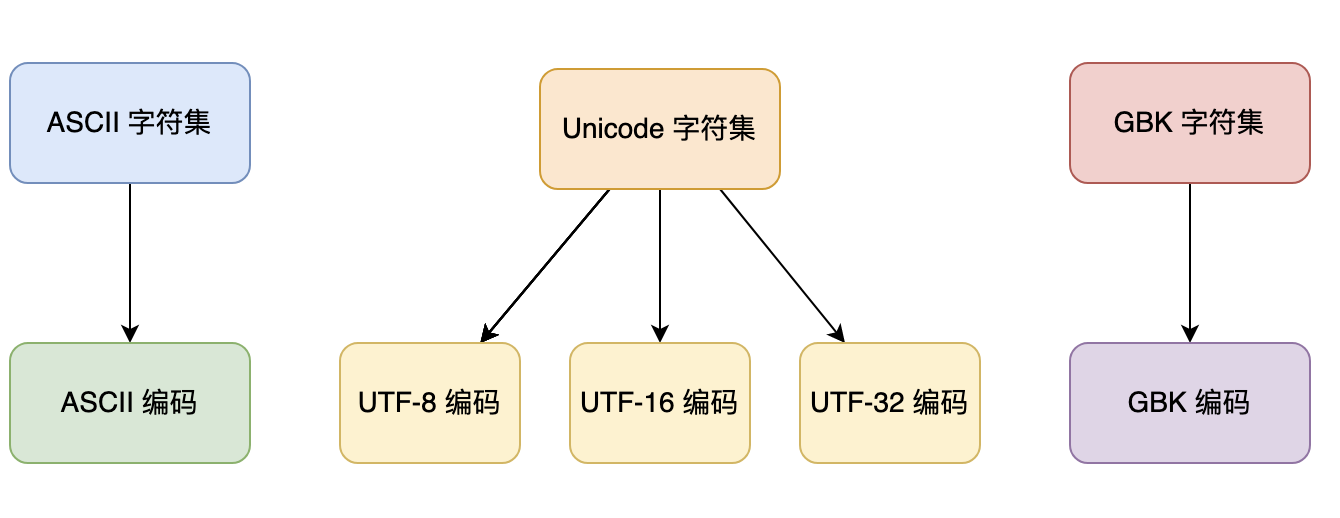
- ASCII字符集
- 一种固定长度的编码方式,每个字符都使用7位二进制编码来表示
- ASCII编码只能表示英文字母、数字和少量符号,不能表示其他语言文字和符号
- Unicode字符集
- UTF-8一种可变长度的编码方式,对于ASCII字符(码点范围为
0x00~0x7F),使用一个字节表示。对于其他 Unicode字符,使用两个、三个或四个字节表示。UTF-8编码方式被广泛应用于互联网和计算机领域,因为它可以有效地压缩数据,适用于网络传输和存储。 - UTF-16一种固定长度的编码方式,对于基本多语言平面(Basic Multilingual Plane,Unicode字符集中的一个码位范围,包含了世界上大部分常用的字符,总共包含了超过65,000个码位)中的字符(码点范围为
0x0000~0xFFFF),使用两个字节表示。对于其他 Unicode 字符,使用四个字节表示。 - UTF-32一种固定长度的编码方式,对于所有Unicode字符,使用四个字节表示
- UTF-8一种可变长度的编码方式,对于ASCII字符(码点范围为
- GBK字符集
- GB2312字符集中的字符,同时还扩展了许多其他汉字字符和符号
- 采用双字节编码方式,一种变长的编码方式,对于 ASCII 字符(码位范围为 0x00 到 0x7F),使用一个字节表示,对于其他字符,使用两个字节表示。每个汉字占用2个字节。
NoClassDefFoundError和ClassNotFoundException区别
都是由于系统运行时找不到要加载的类导致的,但是触发原因不一样
- NoClassDefFoundError:程序在编译时可以找到所依赖的类,但是在运行时找不到指定的类文件,导致抛出该错误;原因可能是jar包缺失或者调用了初始化失败的类。
- ClassNotFoundException:当动态加载Class对象的时候找不到对应的类时抛出该异常;原因可能是要加载的类不存在或者类名写错了
System.exit()
- 终止当前运行的Java虚拟机。参数用作状态码,非0表示异常终止,0表示正常退出程序
- 该方法调用Runtime类中的exit方法,此方法不会正常返回
直接与非直接缓冲区
直接缓冲区和非直接缓冲区的差别主要在于它们在内存中的存储方式。
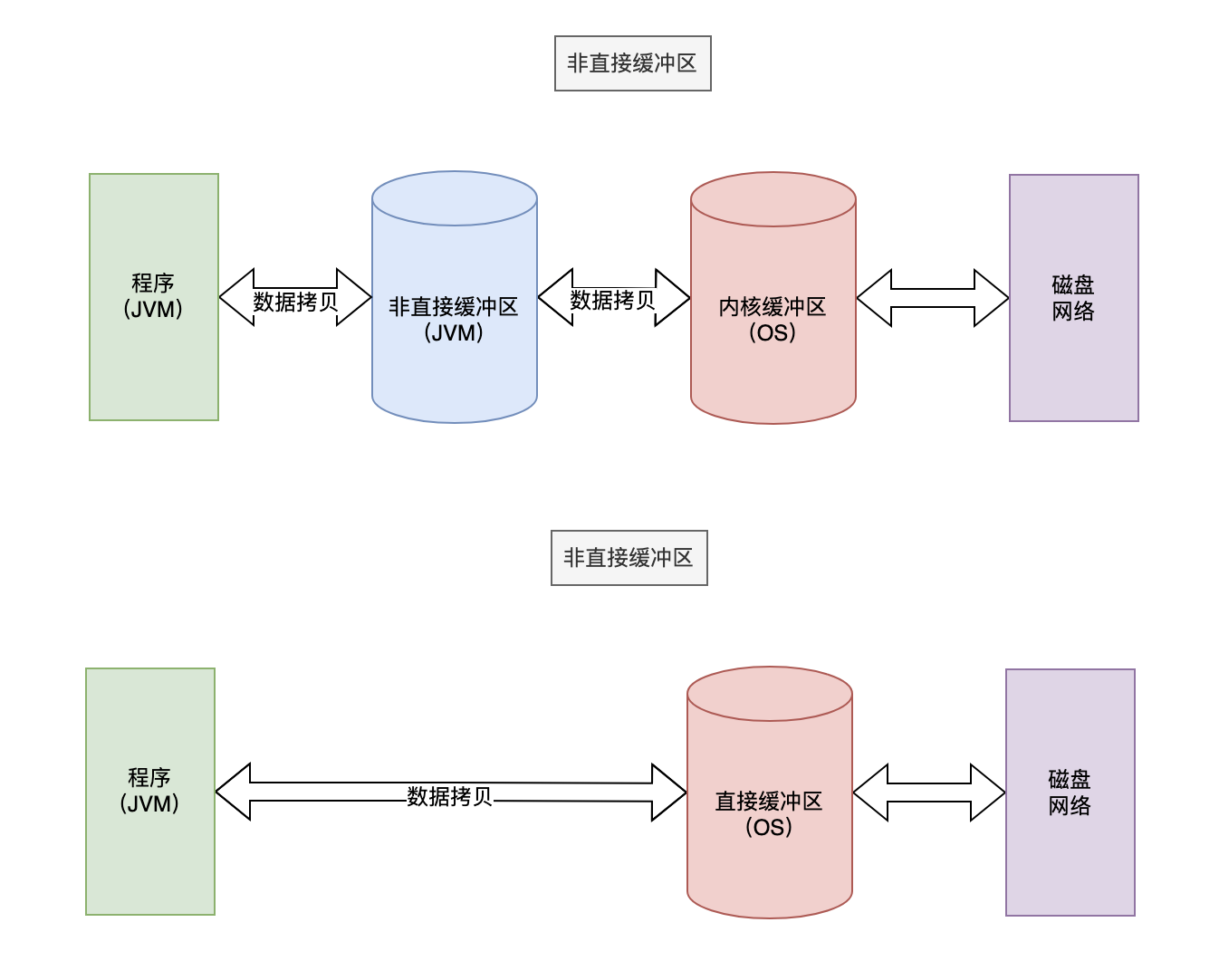
非直接缓冲区:
- 分配在JVM堆内存中
- 受到垃圾回收的管理
- 在读写操作时,需要将数据从堆内存复制到操作系统的本地内存,再进行I/O操作
- 创建:
ByteBuffer.allocate(int capacity)
直接缓冲区:
- 分配在操作系统的本地内存中
- 不受垃圾回收的管理
- 在读写操作时,直接在本地内存中进行,避免了数据复制,提高了性能
- 创建:
ByteBuffer.allocateDirect(int capacity)FileChannel.map()方法,会返回一个类型为MappedByteBuffer的直接缓冲区。